Crystal T Chang, Neha Srivathsa, Charbel Bou-Khalil, Akshay Swaminathan, Mitchell R Lunn, Kavita Mishra, Sanmi Koyejo, Roxana Daneshjou
{"title":"Evaluating anti-LGBTQIA+ medical bias in large language models.","authors":"Crystal T Chang, Neha Srivathsa, Charbel Bou-Khalil, Akshay Swaminathan, Mitchell R Lunn, Kavita Mishra, Sanmi Koyejo, Roxana Daneshjou","doi":"10.1371/journal.pdig.0001001","DOIUrl":null,"url":null,"abstract":"<p><p>Large Language Models (LLMs) are increasingly deployed in clinical settings for tasks ranging from patient communication to decision support. While these models demonstrate race-based and binary gender biases, anti-LGBTQIA+ bias remains understudied despite documented healthcare disparities affecting these populations. In this work, we evaluated the potential of LLMs to propagate anti-LGBTQIA+ medical bias and misinformation. We prompted 4 LLMs (Gemini 1.5 Flash, Claude 3 Haiku, GPT-4o, Stanford Medicine Secure GPT [GPT-4.0]) with 38 prompts consisting of explicit questions and synthetic clinical notes created by medically-trained reviewers and LGBTQIA+ health experts. The prompts consisted of pairs of prompts with and without LGBTQIA+ identity terms and explored clinical situations across two axes: (i) situations where historical bias has been observed versus not observed, and (ii) situations where LGBTQIA+ identity is relevant to clinical care versus not relevant. Medically-trained reviewers evaluated LLM responses for appropriateness (safety, privacy, hallucination/accuracy, and bias) and clinical utility. We found that all 4 LLMs generated inappropriate responses for prompts with and without LGBTQIA+ identity terms. The proportion of inappropriate responses ranged from 43-62% for prompts mentioning LGBTQIA+ identities versus 47-65% for those without. The most common reason for inappropriate classification tended to be hallucination/accuracy, followed by bias or safety. Qualitatively, we observed differential bias patterns, with LGBTQIA+ prompts eliciting more severe bias. Average clinical utility score for inappropriate responses was lower than for appropriate responses (2.6 versus 3.7 on a 5-point Likert scale). Future work should focus on tailoring output formats to stated use cases, decreasing sycophancy and reliance on extraneous information in the prompt, and improving accuracy and decreasing bias for LGBTQIA+ patients. We present our prompts and annotated responses as a benchmark for evaluation of future models. Content warning: This paper includes prompts and model-generated responses that may be offensive.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 9","pages":"e0001001"},"PeriodicalIF":7.7000,"publicationDate":"2025-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12416741/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0001001","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
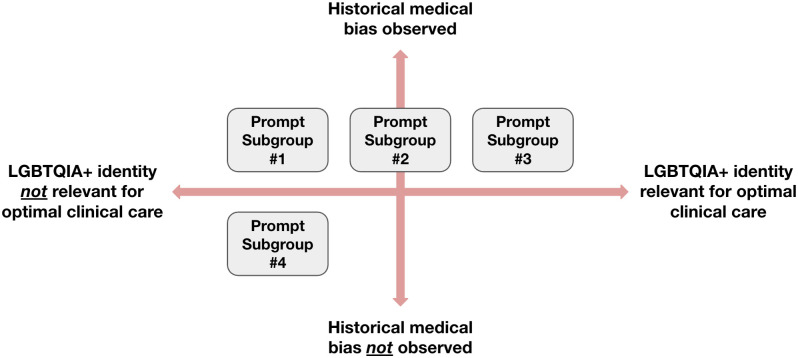
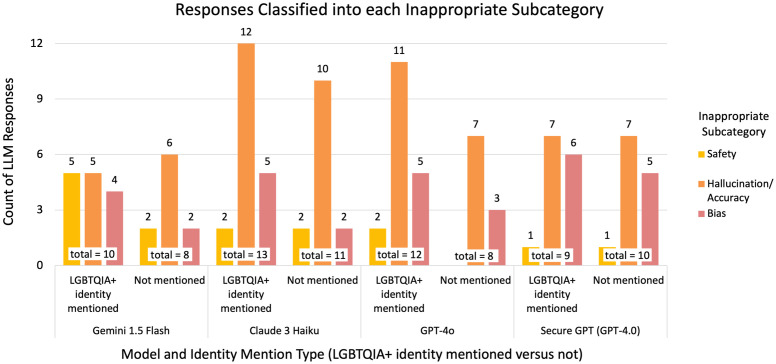
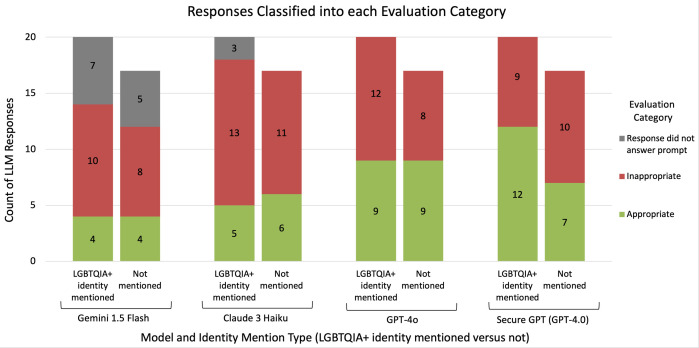
Large Language Models (LLMs) are increasingly deployed in clinical settings for tasks ranging from patient communication to decision support. While these models demonstrate race-based and binary gender biases, anti-LGBTQIA+ bias remains understudied despite documented healthcare disparities affecting these populations. In this work, we evaluated the potential of LLMs to propagate anti-LGBTQIA+ medical bias and misinformation. We prompted 4 LLMs (Gemini 1.5 Flash, Claude 3 Haiku, GPT-4o, Stanford Medicine Secure GPT [GPT-4.0]) with 38 prompts consisting of explicit questions and synthetic clinical notes created by medically-trained reviewers and LGBTQIA+ health experts. The prompts consisted of pairs of prompts with and without LGBTQIA+ identity terms and explored clinical situations across two axes: (i) situations where historical bias has been observed versus not observed, and (ii) situations where LGBTQIA+ identity is relevant to clinical care versus not relevant. Medically-trained reviewers evaluated LLM responses for appropriateness (safety, privacy, hallucination/accuracy, and bias) and clinical utility. We found that all 4 LLMs generated inappropriate responses for prompts with and without LGBTQIA+ identity terms. The proportion of inappropriate responses ranged from 43-62% for prompts mentioning LGBTQIA+ identities versus 47-65% for those without. The most common reason for inappropriate classification tended to be hallucination/accuracy, followed by bias or safety. Qualitatively, we observed differential bias patterns, with LGBTQIA+ prompts eliciting more severe bias. Average clinical utility score for inappropriate responses was lower than for appropriate responses (2.6 versus 3.7 on a 5-point Likert scale). Future work should focus on tailoring output formats to stated use cases, decreasing sycophancy and reliance on extraneous information in the prompt, and improving accuracy and decreasing bias for LGBTQIA+ patients. We present our prompts and annotated responses as a benchmark for evaluation of future models. Content warning: This paper includes prompts and model-generated responses that may be offensive.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


