{"title":"Multi-layer matrix factorization for cancer subtyping using full and partial multi-omics dataset.","authors":"Yingxuan Ren, Fengtao Ren, Bo Yang","doi":"10.1093/bib/bbaf448","DOIUrl":null,"url":null,"abstract":"<p><p>Cancer, with its inherent heterogeneity, is commonly categorized into distinct subtypes based on unique traits, cellular origins, and molecular markers specific to each type. However, current studies primarily rely on complete multi-omics datasets for predicting cancer subtypes, often overlooking predictive performance in cases where some omics data may be missing and neglecting implicit relationships across multiple layers of omics data integration. This paper introduces Multi-Layer Matrix Factorization (MLMF), a novel approach for cancer subtyping that employs multi-omics data clustering. MLMF initially processes multi-omics feature matrices by performing multi-layer linear or nonlinear factorization, decomposing the original data into latent feature representations unique to each omics type. These latent representations are subsequently fused into a consensus form, on which spectral clustering is performed to determine subtypes. Additionally, MLMF incorporates a class indicator matrix to handle missing omics data, creating a unified framework that can manage both complete and incomplete multi-omics data. Extensive experiments conducted on 12 multi-omics cancer datasets, both complete and with missing values, demonstrate that MLMF achieves results that are comparable to or surpass the performance of several state-of-the-art approaches. MLMF is open source and available at (https://github.com/renyingxuan/MLMF.git).</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"26 5","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2025-08-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12418959/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbaf448","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
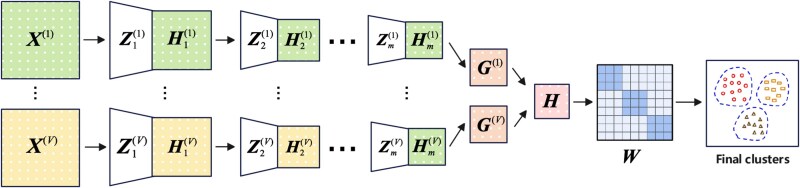
Cancer, with its inherent heterogeneity, is commonly categorized into distinct subtypes based on unique traits, cellular origins, and molecular markers specific to each type. However, current studies primarily rely on complete multi-omics datasets for predicting cancer subtypes, often overlooking predictive performance in cases where some omics data may be missing and neglecting implicit relationships across multiple layers of omics data integration. This paper introduces Multi-Layer Matrix Factorization (MLMF), a novel approach for cancer subtyping that employs multi-omics data clustering. MLMF initially processes multi-omics feature matrices by performing multi-layer linear or nonlinear factorization, decomposing the original data into latent feature representations unique to each omics type. These latent representations are subsequently fused into a consensus form, on which spectral clustering is performed to determine subtypes. Additionally, MLMF incorporates a class indicator matrix to handle missing omics data, creating a unified framework that can manage both complete and incomplete multi-omics data. Extensive experiments conducted on 12 multi-omics cancer datasets, both complete and with missing values, demonstrate that MLMF achieves results that are comparable to or surpass the performance of several state-of-the-art approaches. MLMF is open source and available at (https://github.com/renyingxuan/MLMF.git).
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


