Knowledge-based training of learning architectures under input sensitivity constraints for improved explainability
IF 3.9
2区 工程技术
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
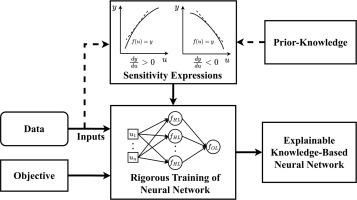
The traditional machine learning (ML) training problem is unconstrained and lacks an explicit formulation of the underlying driving phenomena. Such a formulation, based solely on experimental data, does not ensure the delivery of qualitative knowledge among variables due to many theoretical issues in the optimization task. This study further tightens Artificial Neural Networks (ANNs) training by including input sensitivities as additional constraints and applies to regression and classification tasks based on literature data. In theory, such sensitivity represents the change direction of the target variable per change in measurements from indicators. The resulting nonlinear optimization problem is solved th rough a rigorous solver and includes the sensitivity expressions through algorithmic differentiation. Compared to traditional methods, with an acceptable decrease in the prediction capability, the proposed model delivers more intuitive, explainable, and experimentally verifiable predictions under input variable variations, under robustness to overfitting, while serving robust identification tasks. A classification case study includes a patient-oriented clinical decision support system development based on the impact of cancer-indicating variables. A competitive test prediction accuracy is obtained compared to commonly used algorithms despite 10 % decrease in the training. The regression case is built upon the energy load estimation to account for prominent considerations to obtain desired sensitivity patterns and proposed methodology delivers significant accuracy drop compared to some formulations to address knowledge patterns. The approach delivers a compatible pattern with practitioner expertise and is compared to widely used machine learning algorithms, whose performances are evaluated through common statistics in addition to multi-variable response graphs.
在输入敏感性约束下的基于知识的学习架构训练,以提高可解释性
传统的机器学习(ML)训练问题是不受约束的,缺乏对潜在驱动现象的明确表述。由于优化任务中存在许多理论问题,这种仅基于实验数据的公式不能保证变量间的定性知识传递。本研究通过将输入灵敏度作为附加约束进一步收紧人工神经网络(ann)的训练,并将其应用于基于文献数据的回归和分类任务。理论上,这种灵敏度代表了指标测量值每变化时目标变量的变化方向。所得到的非线性优化问题通过严格求解器求解,并通过算法微分包含灵敏度表达式。与传统方法相比,在可接受的预测能力下降的情况下,该模型在输入变量变化、对过拟合的鲁棒性下提供了更直观、可解释和实验可验证的预测,同时服务于鲁棒识别任务。分类案例研究包括基于癌症指示变量影响的以患者为导向的临床决策支持系统开发。在训练量降低10%的情况下,与常用算法相比,获得了具有竞争力的测试预测精度。回归案例建立在能量负荷估计的基础上,考虑了获得所需灵敏度模式的重要考虑因素,与解决知识模式的一些公式相比,所提出的方法提供了显着的准确性下降。该方法提供了与从业者专业知识兼容的模式,并与广泛使用的机器学习算法进行了比较,机器学习算法的性能通过常见统计数据和多变量响应图进行评估。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computers & Chemical Engineering
工程技术-工程:化工
CiteScore
8.70
自引率
14.00%
发文量
374
审稿时长
70 days
期刊介绍:
Computers & Chemical Engineering is primarily a journal of record for new developments in the application of computing and systems technology to chemical engineering problems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


