Souvik Ghosh, Md Muhaiminul Islam Nafi, M Saifur Rahman
{"title":"ResLysEmbed: a ResNet-based framework for succinylated lysine residue prediction using sequence and language model embeddings.","authors":"Souvik Ghosh, Md Muhaiminul Islam Nafi, M Saifur Rahman","doi":"10.1093/bioadv/vbaf198","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Lysine (K) succinylation is a crucial post-translational modification involved in cellular homeostasis and metabolism, and has been linked to several diseases in recent research. Despite its emerging importance, current computational methods are limited in performance for predicting succinylation sites.</p><p><strong>Results: </strong>We propose ResLysEmbed, a novel ResNet-based architecture that combines traditional word embeddings with per-residue embeddings from protein language models for succinylation site prediction. We also compared multiple protein language models to identify the most effective one for this task. Additionally, we experimented with several deep learning architectures to find the most suitable one for processing word embedding features and developed three hybrid architectures: ConvLysEmbed, InceptLysEmbed, and ResLysEmbed. Among these, ResLysEmbed achieved superior performance with accuracy, MCC, and F1 scores of 0.81, 0.39, 0.40 and 0.72, 0.44, 0.67 on two independent test sets, outperforming existing methods. Furthermore, we applied shapley additive explanations analysis to interpret the influence of each residue within the 33-length window around the target site on the model's predictions. This analysis helps understand how the sequential position and structural distance of residues from the target site affect their contribution to succinylation prediction.</p><p><strong>Availability: </strong>The implementation details and code are available at https://github.com/Sheldor7701/ResLysEmbed.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf198"},"PeriodicalIF":2.8000,"publicationDate":"2025-08-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12413228/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf198","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: Lysine (K) succinylation is a crucial post-translational modification involved in cellular homeostasis and metabolism, and has been linked to several diseases in recent research. Despite its emerging importance, current computational methods are limited in performance for predicting succinylation sites.
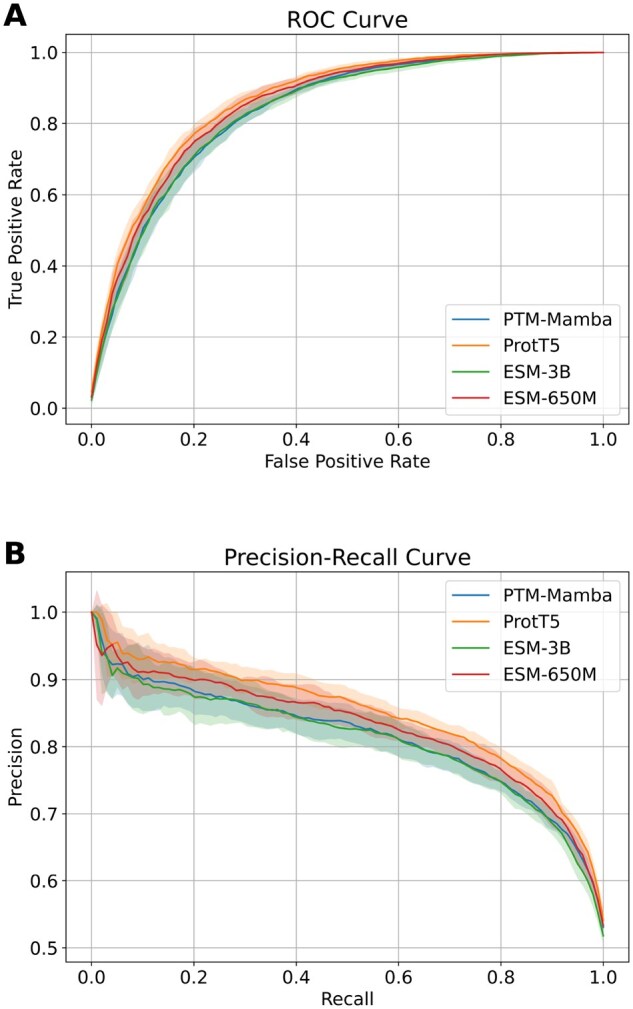
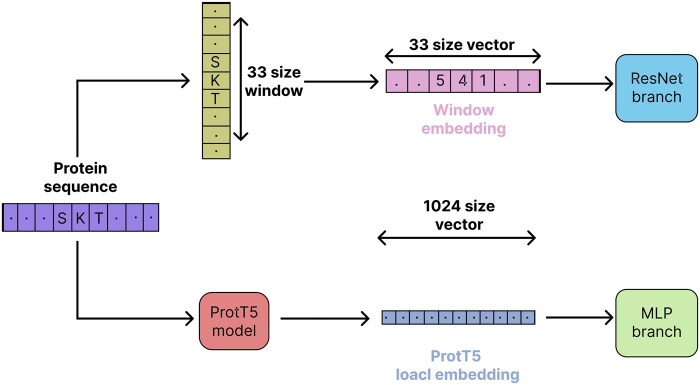
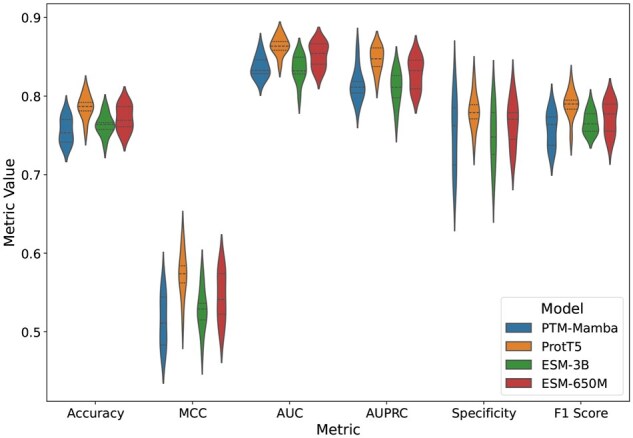
Results: We propose ResLysEmbed, a novel ResNet-based architecture that combines traditional word embeddings with per-residue embeddings from protein language models for succinylation site prediction. We also compared multiple protein language models to identify the most effective one for this task. Additionally, we experimented with several deep learning architectures to find the most suitable one for processing word embedding features and developed three hybrid architectures: ConvLysEmbed, InceptLysEmbed, and ResLysEmbed. Among these, ResLysEmbed achieved superior performance with accuracy, MCC, and F1 scores of 0.81, 0.39, 0.40 and 0.72, 0.44, 0.67 on two independent test sets, outperforming existing methods. Furthermore, we applied shapley additive explanations analysis to interpret the influence of each residue within the 33-length window around the target site on the model's predictions. This analysis helps understand how the sequential position and structural distance of residues from the target site affect their contribution to succinylation prediction.
Availability: The implementation details and code are available at https://github.com/Sheldor7701/ResLysEmbed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


