Philip T L C Clausen, Malte B Hallgren, Søren Overballe-Petersen, Vanessa R Marcelino, Henrik Hasman, Frank M Aarestrup
{"title":"Assembly-free typing of Nanopore and Illumina data through proximity scoring with KMA.","authors":"Philip T L C Clausen, Malte B Hallgren, Søren Overballe-Petersen, Vanessa R Marcelino, Henrik Hasman, Frank M Aarestrup","doi":"10.1093/nargab/lqaf116","DOIUrl":null,"url":null,"abstract":"<p><p>Advances in Oxford Nanopore Technologies (ONT) with the introduction of the r10.4.1 flow cell have reduced the sequencing error rates to <1%. When a reference sequence is known, this allows for accurate variant calling comparable with what is known from the second-generation short-read sequencing technologies, such as Illumina. Additionally, the longer sequence reads provided by ONT enable more efficient mappings, which means the amount of multimapping reads is reduced. However, when the correct reference is not known in advance, and the target reference is highly similar to other references, the multimapping problem is still a concern. Although the <i>ConClave</i> algorithm has provided an accurate solution to the multimapping problem of the second-generation short-read sequencing technologies, it is less effective when resolving the multimapping problems arising from third-generation long-read sequencing technologies. To overcome this problem, we are introducing proximity scoring of alleles, which aids the <i>ConClave</i> algorithm to accurately assign specific alleles from databases containing loci with a high degree of redundancy. Using multilocus sequence typing as a test case, we show that this approach matches the results obtained from sequencing data of Illumina while using limited computational resources that essentially correspond to that of today's smartphones.</p>","PeriodicalId":33994,"journal":{"name":"NAR Genomics and Bioinformatics","volume":"7 3","pages":"lqaf116"},"PeriodicalIF":2.8000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12408904/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NAR Genomics and Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/nargab/lqaf116","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
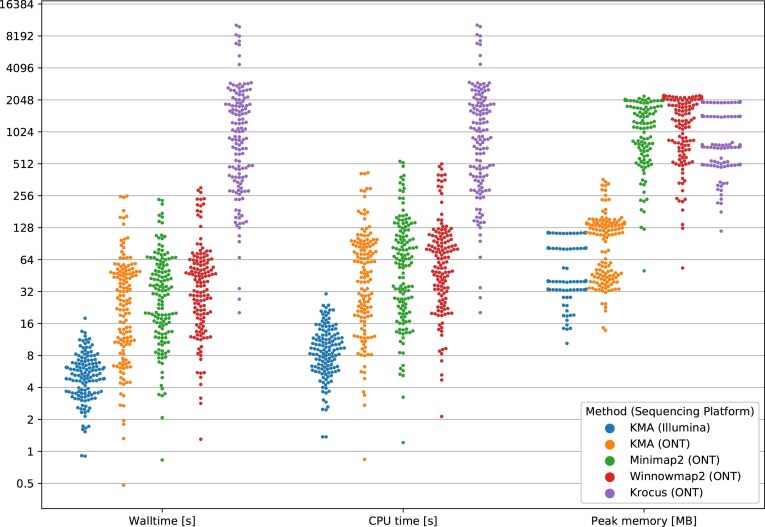
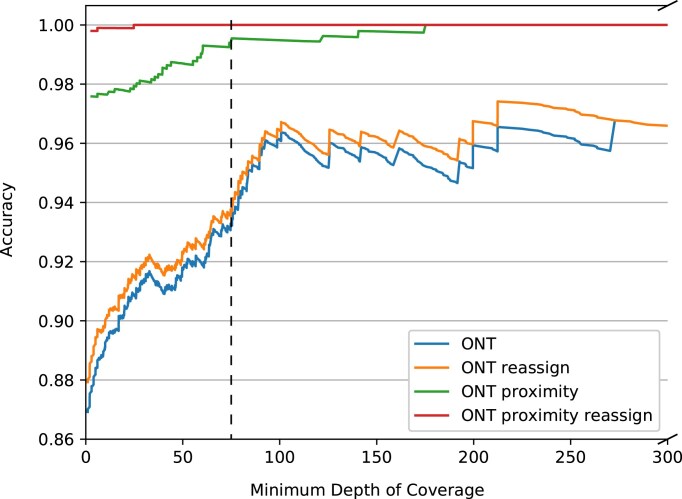
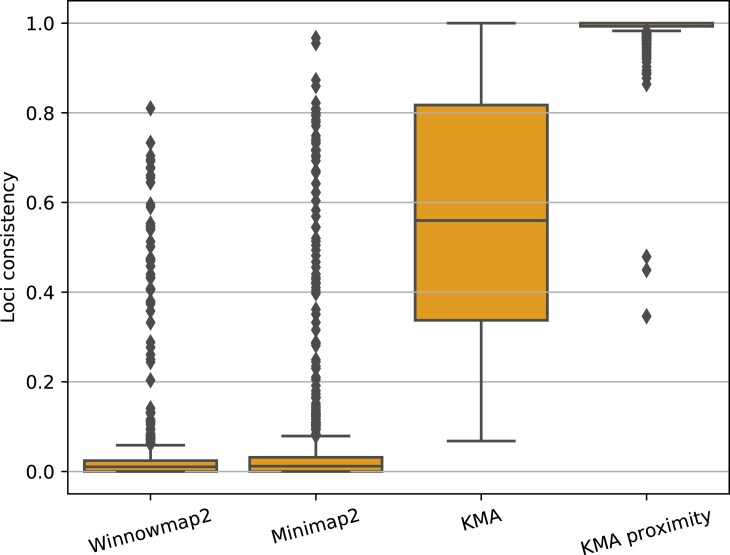
Advances in Oxford Nanopore Technologies (ONT) with the introduction of the r10.4.1 flow cell have reduced the sequencing error rates to <1%. When a reference sequence is known, this allows for accurate variant calling comparable with what is known from the second-generation short-read sequencing technologies, such as Illumina. Additionally, the longer sequence reads provided by ONT enable more efficient mappings, which means the amount of multimapping reads is reduced. However, when the correct reference is not known in advance, and the target reference is highly similar to other references, the multimapping problem is still a concern. Although the ConClave algorithm has provided an accurate solution to the multimapping problem of the second-generation short-read sequencing technologies, it is less effective when resolving the multimapping problems arising from third-generation long-read sequencing technologies. To overcome this problem, we are introducing proximity scoring of alleles, which aids the ConClave algorithm to accurately assign specific alleles from databases containing loci with a high degree of redundancy. Using multilocus sequence typing as a test case, we show that this approach matches the results obtained from sequencing data of Illumina while using limited computational resources that essentially correspond to that of today's smartphones.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


