Camron D Ford, Thomas Bodley, Martin Betts, Rob A Fowler, Alexis Gordon, Michele James, Shail Rawal, Christina Reppas-Rindlisbacher, Paul Tam, George Tomlinson, Christopher J Yarnell
{"title":"Accuracy of preferred language data in a multi-hospital electronic health record in Toronto, Canada.","authors":"Camron D Ford, Thomas Bodley, Martin Betts, Rob A Fowler, Alexis Gordon, Michele James, Shail Rawal, Christina Reppas-Rindlisbacher, Paul Tam, George Tomlinson, Christopher J Yarnell","doi":"10.1371/journal.pdig.0000999","DOIUrl":null,"url":null,"abstract":"<p><p>Accurate preferred language data is a prerequisite for providing high-quality care. We investigated the accuracy of preferred language data in the electronic health record (EHR) of a large community hospital network in Toronto, Canada. We conducted a point-prevalence audit of patients admitted to intensive care, internal medicine, and nephrology services at three hospitals. We asked each patient \"What is your preferred language for health care communication?\" and reported on agreement (with 95% confidence intervals [CI]) between interview-based and EHR-based preferred language. We used Bayesian multilevel logistic regression to analyze the association between patient factors and the accuracy of the EHR for patients who preferred a non-English language. Between June 17, 2024, and July 19, 2024, we interviewed 323 patients, of whom 124 (38%) preferred a non-English language. Median age was 77 years and 46% were female. EHR accuracy was 86% for all patients. The probability of the EHR correctly identifying a patient with non-English preferred language (sensitivity) was 69% (CI 60-77), specificity was 97% (CI 94-99), positive predictive value was 95% (CI 88-98), and negative predictive value was 83% (CI 79-87). There were 26 different non-English preferred languages, most commonly Cantonese (27%) and Tamil (14%). Accuracy was better for patients who were female or older, and varied by hospital and medical service. Mechanisms to improve accuracy for language preference data are needed to improve the validity of research studying preferred language, mitigate algorithmic bias, and overcome language-based inequities.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 9","pages":"e0000999"},"PeriodicalIF":7.7000,"publicationDate":"2025-09-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12407390/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000999","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/9/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
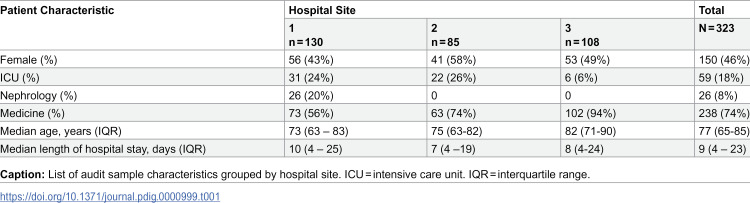
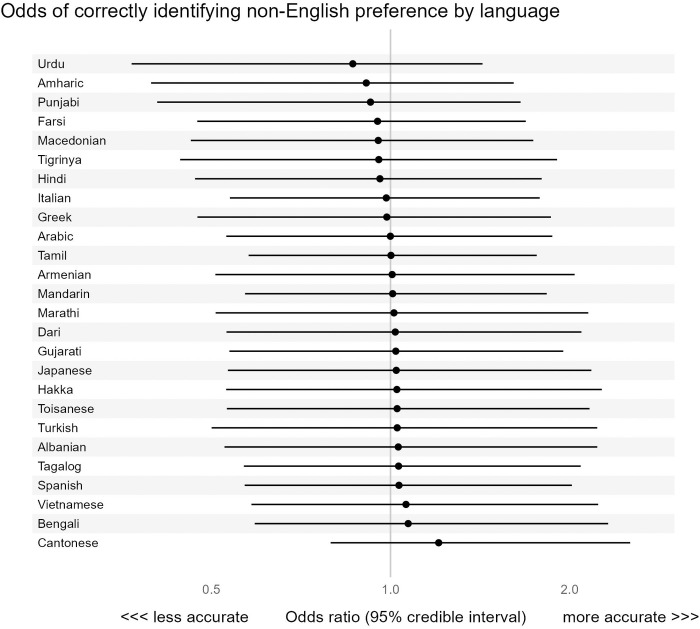
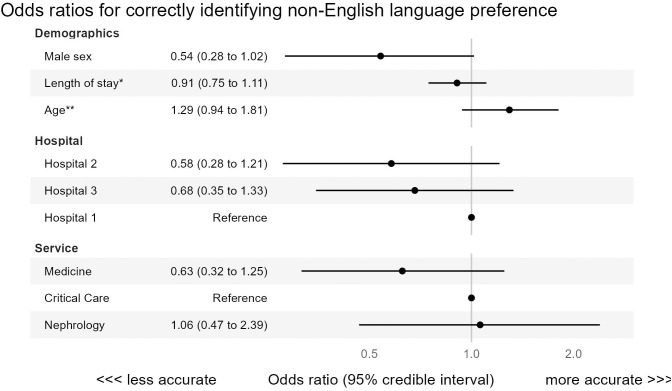
Accurate preferred language data is a prerequisite for providing high-quality care. We investigated the accuracy of preferred language data in the electronic health record (EHR) of a large community hospital network in Toronto, Canada. We conducted a point-prevalence audit of patients admitted to intensive care, internal medicine, and nephrology services at three hospitals. We asked each patient "What is your preferred language for health care communication?" and reported on agreement (with 95% confidence intervals [CI]) between interview-based and EHR-based preferred language. We used Bayesian multilevel logistic regression to analyze the association between patient factors and the accuracy of the EHR for patients who preferred a non-English language. Between June 17, 2024, and July 19, 2024, we interviewed 323 patients, of whom 124 (38%) preferred a non-English language. Median age was 77 years and 46% were female. EHR accuracy was 86% for all patients. The probability of the EHR correctly identifying a patient with non-English preferred language (sensitivity) was 69% (CI 60-77), specificity was 97% (CI 94-99), positive predictive value was 95% (CI 88-98), and negative predictive value was 83% (CI 79-87). There were 26 different non-English preferred languages, most commonly Cantonese (27%) and Tamil (14%). Accuracy was better for patients who were female or older, and varied by hospital and medical service. Mechanisms to improve accuracy for language preference data are needed to improve the validity of research studying preferred language, mitigate algorithmic bias, and overcome language-based inequities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


