{"title":"Panaln: indexing pangenome for read alignment.","authors":"Lilu Guo, Zongtao He, Hongwei Huo","doi":"10.1093/bioinformatics/btaf476","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Pangenome indexing is a critical supporting technology in biological sequence analysis such as read alignment applications. The need to accurately identify billions of small sequencing fragments carrying sequencing errors and genomic variants drives the development of scalable and efficient pangenome indexing approach.</p><p><strong>Results: </strong>We propose a new wavelet tree-based approach, called Panaln, for indexing pangenome and introduce a batch computation approach for fast count query over Panaln. We present a simple and effective seeding strategy and develop a pangenome program that uses the seed-and-extend paradigm for read alignment. Experimental results on simulated and real data demonstrate that Panaln uses significantly less space for the compared pangenome methods with generally higher accuracy. We provide a scalable index construction by representing pangenome with a linear model. Additionally, Panaln brings enhanced accuracy compared to the popular single reference methods.</p><p><strong>Availability and implementation: </strong>Package: https://anaconda.org/bioconda/panaln and source code: https://github.com/Lilu-guo/Panaln.</p>","PeriodicalId":93899,"journal":{"name":"Bioinformatics (Oxford, England)","volume":" ","pages":""},"PeriodicalIF":5.4000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12448906/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics (Oxford, England)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioinformatics/btaf476","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: Pangenome indexing is a critical supporting technology in biological sequence analysis such as read alignment applications. The need to accurately identify billions of small sequencing fragments carrying sequencing errors and genomic variants drives the development of scalable and efficient pangenome indexing approach.
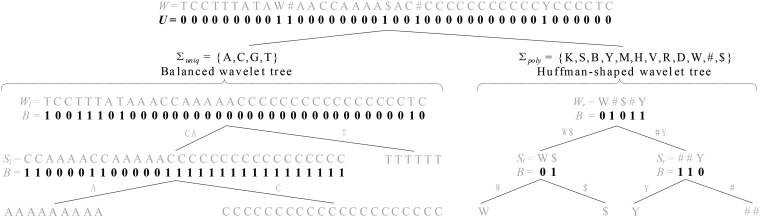
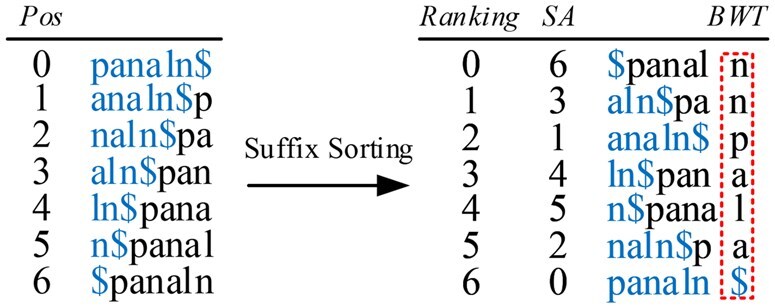
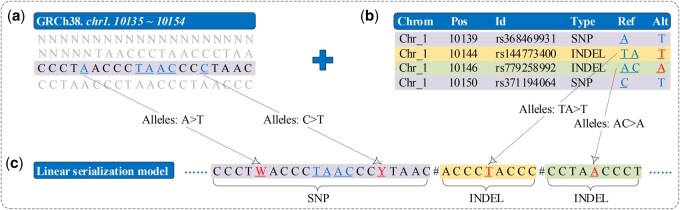
Results: We propose a new wavelet tree-based approach, called Panaln, for indexing pangenome and introduce a batch computation approach for fast count query over Panaln. We present a simple and effective seeding strategy and develop a pangenome program that uses the seed-and-extend paradigm for read alignment. Experimental results on simulated and real data demonstrate that Panaln uses significantly less space for the compared pangenome methods with generally higher accuracy. We provide a scalable index construction by representing pangenome with a linear model. Additionally, Panaln brings enhanced accuracy compared to the popular single reference methods.
Availability and implementation: Package: https://anaconda.org/bioconda/panaln and source code: https://github.com/Lilu-guo/Panaln.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


