{"title":"Rapidly Benchmarking Large Language Models for Diagnosing Comorbid Patients: Comparative Study Leveraging the LLM-as-a-Judge Method.","authors":"Peter Sarvari, Zaid Al-Fagih","doi":"10.2196/67661","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>On average, 1 in 10 patients die because of a diagnostic error, and medical errors represent the third largest cause of death in the United States. While large language models (LLMs) have been proposed to aid doctors in diagnoses, no research results have been published comparing the diagnostic abilities of many popular LLMs on a large, openly accessible real-patient cohort.</p><p><strong>Objective: </strong>In this study, we set out to compare the diagnostic ability of 18 LLMs from Google, OpenAI, Meta, Mistral, Cohere, and Anthropic, using 3 prompts, 2 temperature settings, and 1000 randomly selected Medical Information Mart for Intensive Care-IV (MIMIC-IV) hospital admissions. We also explore improving the diagnostic hit rate of GPT-4o 05-13 with retrieval-augmented generation (RAG) by utilizing reference ranges provided by the American Board of Internal Medicine.</p><p><strong>Methods: </strong>We evaluated the diagnostic ability of 21 LLMs, using an LLM-as-a-judge approach (an automated, LLM-based evaluation) on MIMIC-IV patient records, which contain final diagnostic codes. For each case, a separate assessor LLM (\"judge\") compared the predictor LLM's diagnostic output to the true diagnoses from the patient record. The assessor determined whether each true diagnosis was inferable from the available data and, if so, whether it was correctly predicted (\"hit\") or not (\"miss\"). Diagnoses not inferable from the patient record were excluded from the hit rate analysis. The reported hit rate was defined as the number of hits divided by the total number of hits and misses. The statistical significance of the differences in model performance was assessed using a pooled z-test for proportions.</p><p><strong>Results: </strong>Gemini 2.5 was the top performer with a hit rate of 97.4% (95% CI 97.0%-97.8%) as assessed by GPT-4.1, significantly outperforming GPT-4.1, Claude-4 Opus, and Claude Sonnet. However, GPT-4.1 ranked the highest in a separate set of experiments evaluated by GPT-4 Turbo, which tended to be less conservative than GPT-4.1 in its assessments. Significant variation in diagnostic hit rates was observed across different prompts, while changes in temperature generally had little effect. Finally, RAG significantly improved the hit rate of GPT-4o 05-13 by an average of 0.8% (P<.006).</p><p><strong>Conclusions: </strong>While the results are promising, more diverse datasets and hospital pilots, as well as close collaborations with physicians, are needed to obtain a better understanding of the diagnostic abilities of these models.</p>","PeriodicalId":73558,"journal":{"name":"JMIRx med","volume":"6 ","pages":"e67661"},"PeriodicalIF":0.0000,"publicationDate":"2025-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396308/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIRx med","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/67661","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: On average, 1 in 10 patients die because of a diagnostic error, and medical errors represent the third largest cause of death in the United States. While large language models (LLMs) have been proposed to aid doctors in diagnoses, no research results have been published comparing the diagnostic abilities of many popular LLMs on a large, openly accessible real-patient cohort.
Objective: In this study, we set out to compare the diagnostic ability of 18 LLMs from Google, OpenAI, Meta, Mistral, Cohere, and Anthropic, using 3 prompts, 2 temperature settings, and 1000 randomly selected Medical Information Mart for Intensive Care-IV (MIMIC-IV) hospital admissions. We also explore improving the diagnostic hit rate of GPT-4o 05-13 with retrieval-augmented generation (RAG) by utilizing reference ranges provided by the American Board of Internal Medicine.
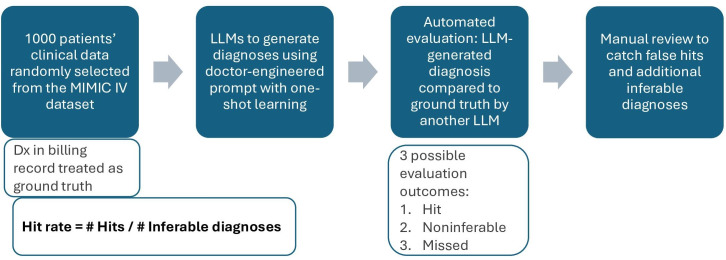
Methods: We evaluated the diagnostic ability of 21 LLMs, using an LLM-as-a-judge approach (an automated, LLM-based evaluation) on MIMIC-IV patient records, which contain final diagnostic codes. For each case, a separate assessor LLM ("judge") compared the predictor LLM's diagnostic output to the true diagnoses from the patient record. The assessor determined whether each true diagnosis was inferable from the available data and, if so, whether it was correctly predicted ("hit") or not ("miss"). Diagnoses not inferable from the patient record were excluded from the hit rate analysis. The reported hit rate was defined as the number of hits divided by the total number of hits and misses. The statistical significance of the differences in model performance was assessed using a pooled z-test for proportions.
Results: Gemini 2.5 was the top performer with a hit rate of 97.4% (95% CI 97.0%-97.8%) as assessed by GPT-4.1, significantly outperforming GPT-4.1, Claude-4 Opus, and Claude Sonnet. However, GPT-4.1 ranked the highest in a separate set of experiments evaluated by GPT-4 Turbo, which tended to be less conservative than GPT-4.1 in its assessments. Significant variation in diagnostic hit rates was observed across different prompts, while changes in temperature generally had little effect. Finally, RAG significantly improved the hit rate of GPT-4o 05-13 by an average of 0.8% (P<.006).
Conclusions: While the results are promising, more diverse datasets and hospital pilots, as well as close collaborations with physicians, are needed to obtain a better understanding of the diagnostic abilities of these models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


