Arjun Singh, Shadi Sartipi, Haoqi Sun, Rebecca Milde, Niels Turley, Carson Quinn, G Kyle Harrold, Rebecca L Gillani, Sarah E Turbett, Sudeshna Das, Sahar Zafar, Marta Fernandes, M Brandon Westover, Shibani S Mukerji
{"title":"A Machine Learning Approach for Identifying People With Neuroinfectious Diseases in Electronic Health Records: Algorithm Development and Validation.","authors":"Arjun Singh, Shadi Sartipi, Haoqi Sun, Rebecca Milde, Niels Turley, Carson Quinn, G Kyle Harrold, Rebecca L Gillani, Sarah E Turbett, Sudeshna Das, Sahar Zafar, Marta Fernandes, M Brandon Westover, Shibani S Mukerji","doi":"10.2196/63157","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Identifying neuroinfectious disease (NID) cases using International Classification of Diseases billing codes is often imprecise, while manual chart reviews are labor-intensive. Machine learning models can leverage unstructured electronic health records to detect subtle NID indicators, process large data volumes efficiently, and reduce misclassification. While accurate NID classification is needed for research and clinical decision support, using unstructured notes for this purpose remains underexplored.</p><p><strong>Objective: </strong>The objective of this study is to develop and validate a machine learning model to identify NIDs from unstructured patient notes.</p><p><strong>Methods: </strong>Clinical notes from patients who had undergone lumbar puncture were obtained using the electronic health record of an academic hospital network (Mass General Brigham [MGB]), with half associated with NID-related diagnostic codes. Ground truth was established by chart review with 6 NID-expert physicians. NID keywords were generated with regular expressions, and extracted texts were converted into bag-of-words representations using n-grams (n=1, 2, 3). Notes were randomly split into training (80%), 2400 notes out of 3000, and hold-out testing (20%), 600 notes out of 3000, sets. Feature selection was performed using logistic regression with L1 regularization. An extreme gradient boosting (XGBoost) model classified NID cases, and performance was evaluated using the area under the receiver operating curve (AUROC) and the precision-recall curve (AUPRC). The performance of the natural language processing (NLP) model was contrasted with the Llama 3.2 auto-regressive model on the MGB test set. The NLP model was additionally validated on external data from an independent hospital (Beth Israel Deaconess Medical Center [BIDMC]).</p><p><strong>Results: </strong>This study included 3000 patient notes from MGB from January 22, 2010, to September 21, 2023. Of 1284 initial n-gram features, 342 were selected, with the most significant features being \"meningitis,\" \"ventriculitis,\" and \"meningoencephalitis.\" The XGBoost model achieved an AUROC of 0.98 (95% CI 0.96-0.99) and AUPRC of 0.89 (95% CI 0.83-0.94) on MGB test data. In comparison, NID identification using International Classification of Diseases billing codes showed high sensitivity (0.97) but poor specificity (0.59), overestimating NID cases. Llama 3.2 improved specificity (0.94) but had low sensitivity (0.64) and an AUROC of 0.80. In contrast, our NLP model balanced specificity (0.96) and sensitivity (0.84), outperforming both methods in accuracy and reliability on MGB data. When tested on external data from BIDMC, the NLP model maintained an AUROC of 0.98 (95% CI 0.96-0.99), with an AUPRC of 0.78 (95% CI 0.66-0.89).</p><p><strong>Conclusions: </strong>The NLP model accurately identifies NID cases from clinical notes. Validated across 2 independent hospital datasets, the model demonstrates feasibility for large-scale NID research and cohort generation. With further external validation, our results could be more generalizable to other institutions.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e63157"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12396800/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/63157","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Identifying neuroinfectious disease (NID) cases using International Classification of Diseases billing codes is often imprecise, while manual chart reviews are labor-intensive. Machine learning models can leverage unstructured electronic health records to detect subtle NID indicators, process large data volumes efficiently, and reduce misclassification. While accurate NID classification is needed for research and clinical decision support, using unstructured notes for this purpose remains underexplored.
Objective: The objective of this study is to develop and validate a machine learning model to identify NIDs from unstructured patient notes.
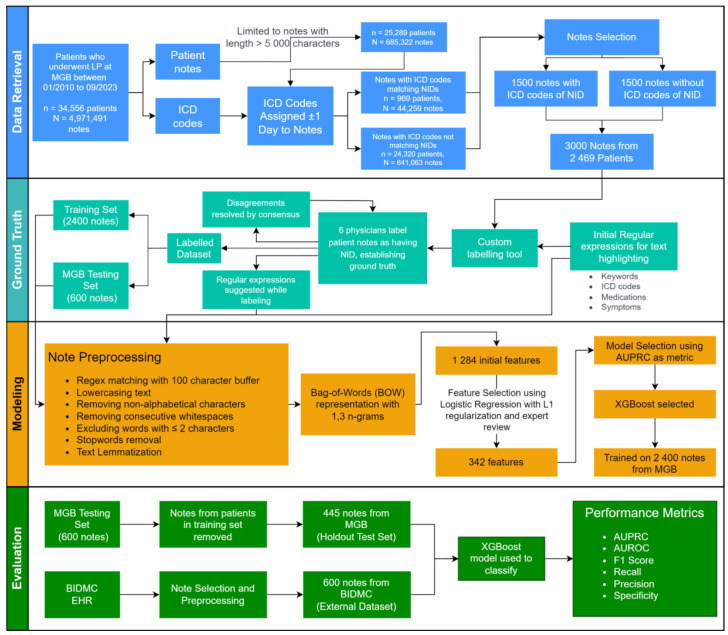
Methods: Clinical notes from patients who had undergone lumbar puncture were obtained using the electronic health record of an academic hospital network (Mass General Brigham [MGB]), with half associated with NID-related diagnostic codes. Ground truth was established by chart review with 6 NID-expert physicians. NID keywords were generated with regular expressions, and extracted texts were converted into bag-of-words representations using n-grams (n=1, 2, 3). Notes were randomly split into training (80%), 2400 notes out of 3000, and hold-out testing (20%), 600 notes out of 3000, sets. Feature selection was performed using logistic regression with L1 regularization. An extreme gradient boosting (XGBoost) model classified NID cases, and performance was evaluated using the area under the receiver operating curve (AUROC) and the precision-recall curve (AUPRC). The performance of the natural language processing (NLP) model was contrasted with the Llama 3.2 auto-regressive model on the MGB test set. The NLP model was additionally validated on external data from an independent hospital (Beth Israel Deaconess Medical Center [BIDMC]).
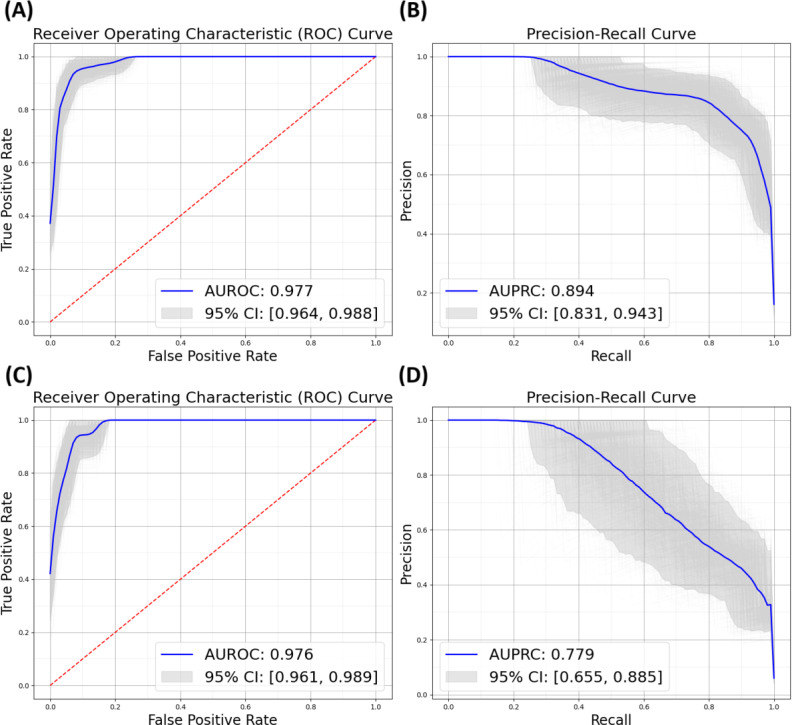
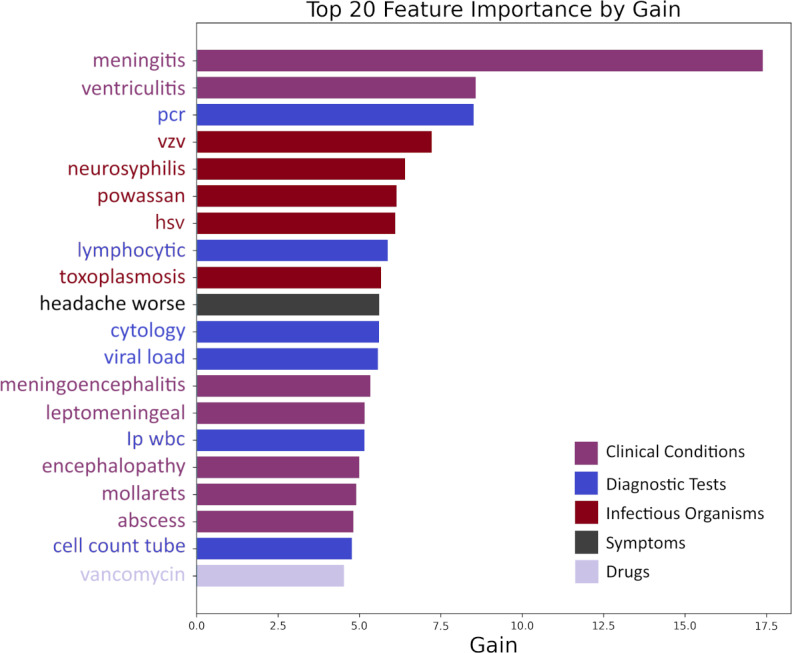
Results: This study included 3000 patient notes from MGB from January 22, 2010, to September 21, 2023. Of 1284 initial n-gram features, 342 were selected, with the most significant features being "meningitis," "ventriculitis," and "meningoencephalitis." The XGBoost model achieved an AUROC of 0.98 (95% CI 0.96-0.99) and AUPRC of 0.89 (95% CI 0.83-0.94) on MGB test data. In comparison, NID identification using International Classification of Diseases billing codes showed high sensitivity (0.97) but poor specificity (0.59), overestimating NID cases. Llama 3.2 improved specificity (0.94) but had low sensitivity (0.64) and an AUROC of 0.80. In contrast, our NLP model balanced specificity (0.96) and sensitivity (0.84), outperforming both methods in accuracy and reliability on MGB data. When tested on external data from BIDMC, the NLP model maintained an AUROC of 0.98 (95% CI 0.96-0.99), with an AUPRC of 0.78 (95% CI 0.66-0.89).
Conclusions: The NLP model accurately identifies NID cases from clinical notes. Validated across 2 independent hospital datasets, the model demonstrates feasibility for large-scale NID research and cohort generation. With further external validation, our results could be more generalizable to other institutions.
背景:使用国际疾病分类账单代码识别神经感染性疾病(NID)病例通常是不精确的,而手工图表审查是劳动密集型的。机器学习模型可以利用非结构化的电子健康记录来检测细微的NID指标,有效地处理大量数据,并减少错误分类。虽然研究和临床决策支持需要准确的NID分类,但使用非结构化笔记用于这一目的仍未得到充分探索。目的:本研究的目的是开发和验证一个机器学习模型,从非结构化的患者笔记中识别NIDs。方法:使用学术医院网络(Mass General Brigham [MGB])的电子健康记录获得腰椎穿刺患者的临床记录,其中一半与nid相关的诊断代码相关。通过与6名nid专家医师进行图表审查,确定了基本事实。使用正则表达式生成NID关键字,提取的文本使用n-gram (n= 1,2,3)转换为词袋表示。音符被随机分为训练组(80%),3000个音符中有2400个音符,以及保留测试组(20%),3000个音符中有600个音符。使用L1正则化逻辑回归进行特征选择。极端梯度增强(XGBoost)模型对NID案例进行分类,并使用接收者工作曲线下面积(AUROC)和精确召回率曲线(AUPRC)来评估性能。在MGB测试集上对比了自然语言处理(NLP)模型与Llama 3.2自回归模型的性能。NLP模型还在一家独立医院(Beth Israel Deaconess Medical Center [BIDMC])的外部数据上进行了验证。结果:本研究纳入MGB 2010年1月22日至2023年9月21日的3000例患者记录。在1284个初始n-gram特征中,选择了342个,其中最重要的特征是“脑膜炎”、“脑室炎”和“脑膜脑炎”。XGBoost模型在MGB测试数据上的AUROC为0.98 (95% CI 0.96-0.99), AUPRC为0.89 (95% CI 0.83-0.94)。相比之下,使用国际疾病分类账单码识别NID的敏感性高(0.97),但特异性较差(0.59),高估了NID病例。Llama 3.2提高了特异性(0.94),但敏感性较低(0.64),AUROC为0.80。相比之下,我们的NLP模型平衡了特异性(0.96)和敏感性(0.84),在MGB数据的准确性和可靠性方面优于两种方法。当对BIDMC的外部数据进行测试时,NLP模型的AUROC为0.98 (95% CI 0.96-0.99), AUPRC为0.78 (95% CI 0.66-0.89)。结论:NLP模型能准确地从临床记录中识别NID病例。通过两个独立的医院数据集验证,该模型证明了大规模NID研究和队列生成的可行性。通过进一步的外部验证,我们的结果可以更广泛地推广到其他机构。
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


