Label Accuracy in Electronic Health Records and Its Impact on Machine Learning Models for Early Prediction of Gestational Diabetes: 3-Step Retrospective Validation Study.
Mark Germaine, Amy C O'Higgins, Brendan Egan, Graham Healy
{"title":"Label Accuracy in Electronic Health Records and Its Impact on Machine Learning Models for Early Prediction of Gestational Diabetes: 3-Step Retrospective Validation Study.","authors":"Mark Germaine, Amy C O'Higgins, Brendan Egan, Graham Healy","doi":"10.2196/72938","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Several studies have used electronic health records (EHRs) to build machine learning models predicting the likelihood of developing gestational diabetes mellitus (GDM) later in pregnancy, but none have described validation of the GDM \"label\" within the EHRs.</p><p><strong>Objective: </strong>This study examines the accuracy of GDM diagnoses in EHRs compared with a clinical team database (CTD) and their impact on machine learning models.</p><p><strong>Methods: </strong>EHRs from 2018 to 2022 were validated against CTD data to identify true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). Logistic regression models were trained and tested using both EHR and validated labels, whereafter simulated label noise was introduced to increase FP and FN rates. Model performance was assessed using the area under the receiver operating characteristic curve (ROC AUC) and average precision (AP).</p><p><strong>Results: </strong>Among 3952 patients, 3388 (85.7%) were correctly identified with GDM in both databases, while 564 cases lacked a GDM label in EHRs, and 771 were missing a corresponding CTD label. Overall, 32,928 (87.5%) of cases were TN, 3388 (9%) TP, 771 (2%) FP, and 564 (1.5%) FN. The model trained and tested with validated labels achieved an ROC AUC of 0.817 and an AP of 0.450, whereas the same model tested using EHR labels achieved 0.814 and 0.395, respectively. Increased label noise during training led to gradual declines in ROC AUC and AP, while noise in the test set, especially elevated FP rates, resulted in marked performance drops.</p><p><strong>Conclusions: </strong>Discrepancies between EHR and CTD diagnoses had a limited impact on model training but significantly affected performance evaluation when present in the test set, emphasizing the importance of accurate data validation.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e72938"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12377786/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/72938","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Several studies have used electronic health records (EHRs) to build machine learning models predicting the likelihood of developing gestational diabetes mellitus (GDM) later in pregnancy, but none have described validation of the GDM "label" within the EHRs.
Objective: This study examines the accuracy of GDM diagnoses in EHRs compared with a clinical team database (CTD) and their impact on machine learning models.
Methods: EHRs from 2018 to 2022 were validated against CTD data to identify true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). Logistic regression models were trained and tested using both EHR and validated labels, whereafter simulated label noise was introduced to increase FP and FN rates. Model performance was assessed using the area under the receiver operating characteristic curve (ROC AUC) and average precision (AP).
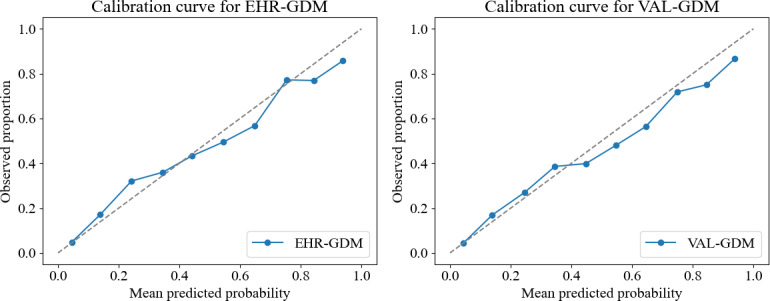
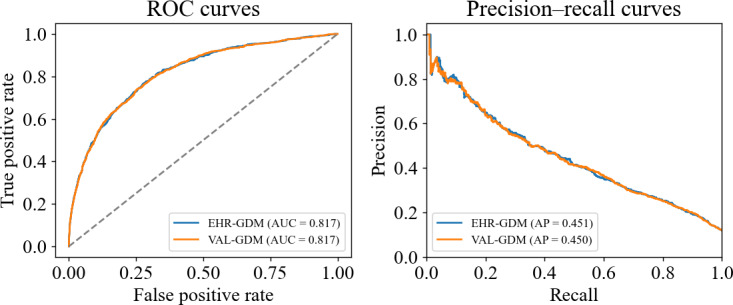
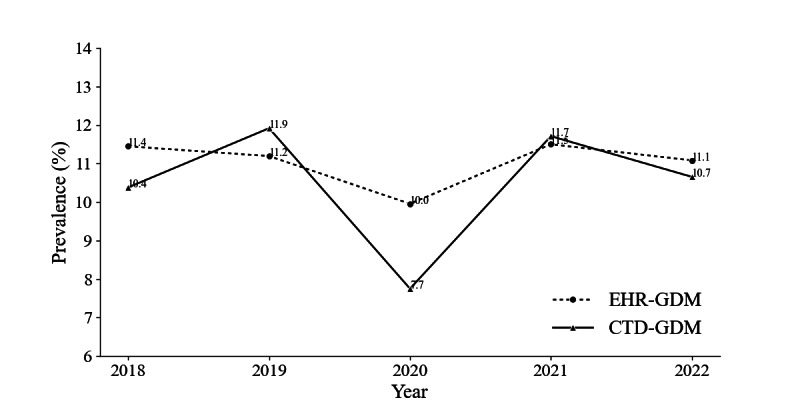
Results: Among 3952 patients, 3388 (85.7%) were correctly identified with GDM in both databases, while 564 cases lacked a GDM label in EHRs, and 771 were missing a corresponding CTD label. Overall, 32,928 (87.5%) of cases were TN, 3388 (9%) TP, 771 (2%) FP, and 564 (1.5%) FN. The model trained and tested with validated labels achieved an ROC AUC of 0.817 and an AP of 0.450, whereas the same model tested using EHR labels achieved 0.814 and 0.395, respectively. Increased label noise during training led to gradual declines in ROC AUC and AP, while noise in the test set, especially elevated FP rates, resulted in marked performance drops.
Conclusions: Discrepancies between EHR and CTD diagnoses had a limited impact on model training but significantly affected performance evaluation when present in the test set, emphasizing the importance of accurate data validation.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


