An Extraction Tool for Venous Thromboembolism Symptom Identification in Primary Care Notes to Facilitate Electronic Clinical Quality Measure Reporting: Algorithm Development and Validation Study.
John Novoa-Laurentiev, Mica Bowen, Avery Pullman, Wenyu Song, Ania Syrowatka, Jin Chen, Michael Sainlaire, Frank Chang, Krissy Gray, Purushottam Panta, Luwei Liu, Khalid Nawab, Shadi Hijjawi, Richard Schreiber, Li Zhou, Patricia C Dykes
{"title":"An Extraction Tool for Venous Thromboembolism Symptom Identification in Primary Care Notes to Facilitate Electronic Clinical Quality Measure Reporting: Algorithm Development and Validation Study.","authors":"John Novoa-Laurentiev, Mica Bowen, Avery Pullman, Wenyu Song, Ania Syrowatka, Jin Chen, Michael Sainlaire, Frank Chang, Krissy Gray, Purushottam Panta, Luwei Liu, Khalid Nawab, Shadi Hijjawi, Richard Schreiber, Li Zhou, Patricia C Dykes","doi":"10.2196/63720","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Diagnosis of venous thromboembolism (VTE) is often delayed, and facilitating earlier diagnosis may improve associated morbidity and mortality. Clinical notes contain information not found elsewhere in the medical record that could facilitate timely VTE diagnosis and accurate quality measurement. However, extracting relevant information from unstructured clinical notes is complex. Today, there are relatively few electronic clinical quality measures (eCQMs) in our national payment program and none that use natural language processing (NLP) techniques for data extraction. NLP holds great promise for making quality measurement more accurate and more efficient. Given the potential of NLP-based applications to facilitate more accurate VTE detection, primary care is one clinical setting in urgent need of this type of tool.</p><p><strong>Objective: </strong>This study aimed to develop a tool that extracts VTE symptoms from clinical notes for use within an eCQM to quantify the rate of delayed diagnosis of VTE in primary care settings.</p><p><strong>Methods: </strong>We iteratively developed an NLP-based data extraction tool, venous thromboembolism symptom extractor (VTExt), on an internal dataset using a rule-based approach to extract VTE symptoms from primary care clinical note text. The VTE symptoms lexicon was derived and optimized with physician guidance and externally validated using datasets from 2 independent health care organizations. We performed 26 rounds of performance evaluation of notes sampled from the case cohort (17,585 patient progress note sentences from 279 patient notes), and 5 rounds of evaluation of the control cohort (2838 patient progress note sentences from 50 patient notes). VTExt's performance was evaluated using evaluation metrics, including area under the curve, positive predictive value, negative predictive value, sensitivity, and specificity.</p><p><strong>Results: </strong>VTExt achieved near-perfect performance in extracting VTE symptoms from primary care notes sampled from records of patients diagnosed with or without VTE. In external validation, VTExt achieved promising performance in 2 additional geographically distant organizations using different electronic health record systems. When compared against a deep learning model and 4 machine learning models, VTExt exhibited similar or even improved performance across all metrics.</p><p><strong>Conclusions: </strong>This study demonstrates a data-driven NLP-based approach to clinical note information extraction that can be generalized to different electronic health record systems across different institutions. Due to the robust performance of this tool, VTExt is the first NLP application to be used in a nationally endorsed eCQM.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e63720"},"PeriodicalIF":3.8000,"publicationDate":"2025-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12387394/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/63720","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Diagnosis of venous thromboembolism (VTE) is often delayed, and facilitating earlier diagnosis may improve associated morbidity and mortality. Clinical notes contain information not found elsewhere in the medical record that could facilitate timely VTE diagnosis and accurate quality measurement. However, extracting relevant information from unstructured clinical notes is complex. Today, there are relatively few electronic clinical quality measures (eCQMs) in our national payment program and none that use natural language processing (NLP) techniques for data extraction. NLP holds great promise for making quality measurement more accurate and more efficient. Given the potential of NLP-based applications to facilitate more accurate VTE detection, primary care is one clinical setting in urgent need of this type of tool.
Objective: This study aimed to develop a tool that extracts VTE symptoms from clinical notes for use within an eCQM to quantify the rate of delayed diagnosis of VTE in primary care settings.
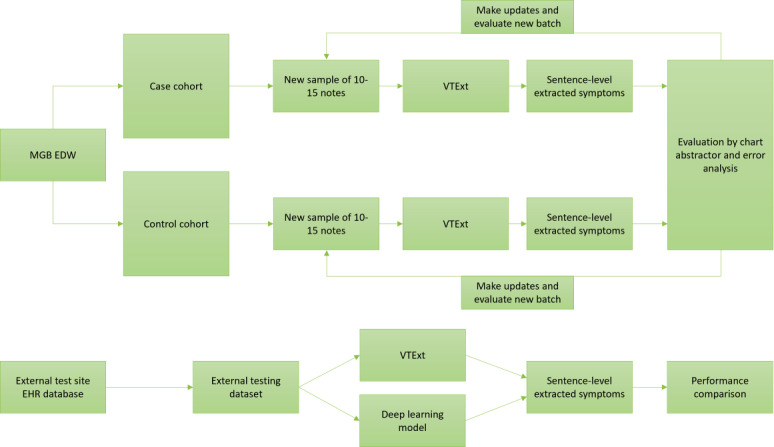
Methods: We iteratively developed an NLP-based data extraction tool, venous thromboembolism symptom extractor (VTExt), on an internal dataset using a rule-based approach to extract VTE symptoms from primary care clinical note text. The VTE symptoms lexicon was derived and optimized with physician guidance and externally validated using datasets from 2 independent health care organizations. We performed 26 rounds of performance evaluation of notes sampled from the case cohort (17,585 patient progress note sentences from 279 patient notes), and 5 rounds of evaluation of the control cohort (2838 patient progress note sentences from 50 patient notes). VTExt's performance was evaluated using evaluation metrics, including area under the curve, positive predictive value, negative predictive value, sensitivity, and specificity.
Results: VTExt achieved near-perfect performance in extracting VTE symptoms from primary care notes sampled from records of patients diagnosed with or without VTE. In external validation, VTExt achieved promising performance in 2 additional geographically distant organizations using different electronic health record systems. When compared against a deep learning model and 4 machine learning models, VTExt exhibited similar or even improved performance across all metrics.
Conclusions: This study demonstrates a data-driven NLP-based approach to clinical note information extraction that can be generalized to different electronic health record systems across different institutions. Due to the robust performance of this tool, VTExt is the first NLP application to be used in a nationally endorsed eCQM.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


