Evaluation of machine learning and logistic regression-based gestational diabetes prognostic models
IF 5.2
2区 医学
Q1 HEALTH CARE SCIENCES & SERVICES
引用次数: 0
Abstract
Objectives
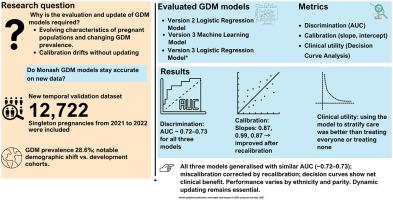
This study aimed to follow best practice by temporally evaluating existing gestational diabetes mellitus (GDM) prediction models, updating them where needed, and comparing the temporal evaluation performance of the machine learning (ML)-based models with that of regression-based models.
Study Design and Setting
We utilized new data for the temporal validation dataset with 12,722 singleton pregnancies at the Monash Health Network from 2021 to 2022. The Monash GDM Logistic Regression (LR) model with six categorical variables (version 2) and the Monash GDM ML model (version 3), along with an extended LR GDM model (version 3), each with eight categorical and continuous variables, were evaluated. Model performance was assessed using discrimination and calibration. Decision curve analyses (DCA) were performed to determine the net benefit of models. Recalibration was considered to improve model performance.
Results
The development datasets for model versions 2, 3, and the new temporal validation dataset included 21.2%, 22.5%, and 33.5% of pregnant women aged ≥35 years, respectively; 22%, 23.7%, and 24.0% with a body mass index ≥30 kg/m2; and GDM prevalence rates of 18%, 21.3%, and 28.6%, respectively. There was similar discrimination performance across the models, with area under the receiver operating characteristic curve (AUC) of 0.72 [95% CI: 0.71, 0.73], 0.73 [95% CI: 0.72, 0.74], and 0.73 [95% CI: 0.73, 0.74] for version 2 and version 3 ML and LR models, respectively. All models exhibited overestimation with calibration slopes of 0.87, 0.99, and 0.87, respectively, which improved with recalibration. DCA showed that all models had better net benefits as compared to treat all and treat none. For all models, some variability has been observed in prediction performance across ethnic groups and parity.
Conclusion
Despite significant changes in the background characteristics of the population, we have demonstrated that all models remained robust, especially after recalibration. However, the performance of the original ML model decreased significantly during validation. Dynamic models are better suited to adapt to the temporal changes in baseline characteristics of pregnant women and the resulting calibration drift, as they can incorporate new data without requiring manual evaluation.
基于机器学习和逻辑回归的妊娠糖尿病预后模型的评估。
目的:本研究旨在遵循最佳实践,对现有GDM预测模型进行时间评估,并在需要时对其进行更新,并比较基于ml的模型与基于回归的模型的时间评估性能。研究设计和设置:我们使用了新的数据,用于时间验证数据集,其中包括2021年至2022年莫纳什健康网络的12,722例单胎妊娠。评估了包含6个分类变量的莫纳什GDM逻辑回归(LR)模型(版本2)和莫纳什GDM机器学习模型(版本3),以及扩展的LR GDM模型(版本3),每个模型都包含8个分类和连续变量。通过判别和校准来评估模型的性能。采用决策曲线分析(DCA)来确定模型的净效益。重新校准被认为可以提高模型的性能。结果:模型版本2、3和新的时间验证数据集的发展数据集分别包括21.2%、22.5%和33.5%的年龄≥35岁的孕妇;22%、23.7%和24.0%的人体重指数(BMI)≥30 kg/m2;GDM患病率分别为18%、21.3%和28.6%。各模型的识别性能相似,版本2和版本3 ML和LR模型的曲线下面积(auc)分别为0.72 [95% CI: 0.71, 0.73]、0.73 [95% CI: 0.72, 0.74]和0.73 [95% CI: 0.73, 0.74]。所有模型均表现出过高估计,校正斜率分别为0.87、0.99和0.87,重新校正后有所改善。DCA显示,所有模型的净效益都优于全部治疗和不治疗。对于所有模型,在跨种族群体和均等性的预测表现中观察到一些可变性。结论:尽管人群的背景特征发生了重大变化,但我们已经证明所有模型仍然是稳健的,特别是在重新校准之后。然而,在验证过程中,原始ML模型的性能明显下降。动态模型更适合于适应孕妇基线特征的时间变化和由此产生的校准漂移,因为它们可以在不需要人工评估的情况下纳入新数据。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Clinical Epidemiology
医学-公共卫生、环境卫生与职业卫生
CiteScore
12.00
自引率
6.90%
发文量
320
审稿时长
44 days
期刊介绍:
The Journal of Clinical Epidemiology strives to enhance the quality of clinical and patient-oriented healthcare research by advancing and applying innovative methods in conducting, presenting, synthesizing, disseminating, and translating research results into optimal clinical practice. Special emphasis is placed on training new generations of scientists and clinical practice leaders.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


