{"title":"Part-Wise Graph Fourier Learning for Skeleton-Based Continuous Sign Language Recognition.","authors":"Dong Wei, Hongxiang Hu, Gang-Feng Ma","doi":"10.3390/jimaging11080286","DOIUrl":null,"url":null,"abstract":"<p><p>Sign language is a visual language articulated through body movements. Existing approaches predominantly leverage RGB inputs, incurring substantial computational overhead and remaining susceptible to interference from foreground and background noise. A second fundamental challenge lies in accurately modeling the nonlinear temporal dynamics and inherent asynchrony across body parts that characterize sign language sequences. To address these challenges, we propose a novel part-wise graph Fourier learning method for skeleton-based continuous sign language recognition (PGF-SLR), which uniformly models the spatiotemporal relations of multiple body parts in a globally ordered yet locally unordered manner. Specifically, different parts within different time steps are treated as nodes, while the frequency domain attention between parts is treated as edges to construct a part-level Fourier fully connected graph. This enables the graph Fourier learning module to jointly capture spatiotemporal dependencies in the frequency domain, while our adaptive frequency enhancement method further amplifies discriminative action features in a lightweight and robust fashion. Finally, a dual-branch action learning module featuring an auxiliary action prediction branch to assist the recognition branch is designed to enhance the understanding of sign language. Our experimental results show that the proposed PGF-SLR achieved relative improvements of 3.31%/3.70% and 2.81%/7.33% compared to SOTA methods on the dev/test sets of the PHOENIX14 and PHOENIX14-T datasets. It also demonstrated highly competitive recognition performance on the CSL-Daily dataset, showcasing strong generalization while reducing computational costs in both offline and online settings.</p>","PeriodicalId":37035,"journal":{"name":"Journal of Imaging","volume":"11 8","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2025-08-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12387829/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Imaging","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/jimaging11080286","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"IMAGING SCIENCE & PHOTOGRAPHIC TECHNOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
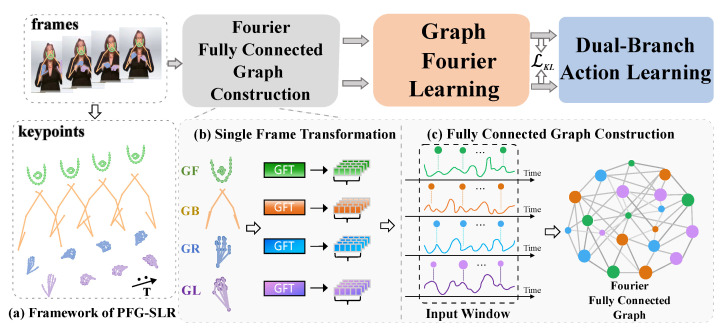
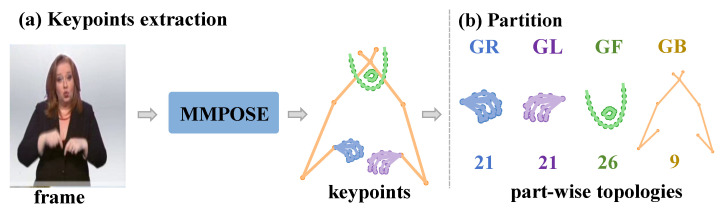
Sign language is a visual language articulated through body movements. Existing approaches predominantly leverage RGB inputs, incurring substantial computational overhead and remaining susceptible to interference from foreground and background noise. A second fundamental challenge lies in accurately modeling the nonlinear temporal dynamics and inherent asynchrony across body parts that characterize sign language sequences. To address these challenges, we propose a novel part-wise graph Fourier learning method for skeleton-based continuous sign language recognition (PGF-SLR), which uniformly models the spatiotemporal relations of multiple body parts in a globally ordered yet locally unordered manner. Specifically, different parts within different time steps are treated as nodes, while the frequency domain attention between parts is treated as edges to construct a part-level Fourier fully connected graph. This enables the graph Fourier learning module to jointly capture spatiotemporal dependencies in the frequency domain, while our adaptive frequency enhancement method further amplifies discriminative action features in a lightweight and robust fashion. Finally, a dual-branch action learning module featuring an auxiliary action prediction branch to assist the recognition branch is designed to enhance the understanding of sign language. Our experimental results show that the proposed PGF-SLR achieved relative improvements of 3.31%/3.70% and 2.81%/7.33% compared to SOTA methods on the dev/test sets of the PHOENIX14 and PHOENIX14-T datasets. It also demonstrated highly competitive recognition performance on the CSL-Daily dataset, showcasing strong generalization while reducing computational costs in both offline and online settings.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


