Deyuan Zhong, Yuxin Liang, Hong-Tao Yan, Xinpei Chen, Qinyan Yang, Shuoshuo Ma, Yuhao Su, YaHui Chen, Xiaolun Huang, Ming Wang
{"title":"A Comparative Study of Five Large Language Models' Response for Liver Cancer Comprehensive Treatment.","authors":"Deyuan Zhong, Yuxin Liang, Hong-Tao Yan, Xinpei Chen, Qinyan Yang, Shuoshuo Ma, Yuhao Su, YaHui Chen, Xiaolun Huang, Ming Wang","doi":"10.2147/JHC.S531642","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Large language models (LLMs) are increasingly used in healthcare, yet their reliability in specialized clinical fields remains uncertain. Liver cancer, as a complex and high-burden disease, poses unique challenges for AI-based tools. This study aimed to evaluate the comprehensibility and clinical applicability of five mainstream LLMs in addressing liver cancer-related clinical questions.</p><p><strong>Methods: </strong>We developed 90 standardized questions covering multiple aspects of liver cancer management. Five LLMs-GPT-4, Gemini, Copilot, Kimi, and Ernie Bot-were evaluated in a blinded fashion by three independent hepatobiliary experts. Responses were scored using predefined criteria for comprehensibility and clinical applicability. Overall group comparisons were conducted using the Fisher-Freeman-Halton test (for categorical data) and the Kruskal-Wallis test (for ordinal scores), followed by Dunn's post-hoc test or Fisher's exact test with Bonferroni correction. Inter-rater reliability was assessed using Fleiss' kappa.</p><p><strong>Results: </strong>Kimi and GPT-4 achieved the highest proportions of fully applicable responses (68% and 62%, respectively), while Ernie Bot and Copilot showed the lowest. Comprehensibility was generally high, with Kimi and Ernie Bot scoring over 98%. However, none of the LLMs consistently provided guideline-concordant answers to all questions. Performance on professional-level questions was significantly lower than on common-sense ones, highlighting deficiencies in complex clinical reasoning.</p><p><strong>Conclusion: </strong>LLMs demonstrate varied performance in liver cancer-related queries. While GPT-4 and Kimi show promise in clinical applicability, limitations in accuracy and consistency-particularly for complex medical decisions-underscore the need for domain-specific optimization before clinical integration.</p><p><strong>Trial registration: </strong>Not applicable.</p>","PeriodicalId":15906,"journal":{"name":"Journal of Hepatocellular Carcinoma","volume":"12 ","pages":"1861-1871"},"PeriodicalIF":3.4000,"publicationDate":"2025-08-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12375359/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Hepatocellular Carcinoma","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2147/JHC.S531642","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"ONCOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Large language models (LLMs) are increasingly used in healthcare, yet their reliability in specialized clinical fields remains uncertain. Liver cancer, as a complex and high-burden disease, poses unique challenges for AI-based tools. This study aimed to evaluate the comprehensibility and clinical applicability of five mainstream LLMs in addressing liver cancer-related clinical questions.
Methods: We developed 90 standardized questions covering multiple aspects of liver cancer management. Five LLMs-GPT-4, Gemini, Copilot, Kimi, and Ernie Bot-were evaluated in a blinded fashion by three independent hepatobiliary experts. Responses were scored using predefined criteria for comprehensibility and clinical applicability. Overall group comparisons were conducted using the Fisher-Freeman-Halton test (for categorical data) and the Kruskal-Wallis test (for ordinal scores), followed by Dunn's post-hoc test or Fisher's exact test with Bonferroni correction. Inter-rater reliability was assessed using Fleiss' kappa.
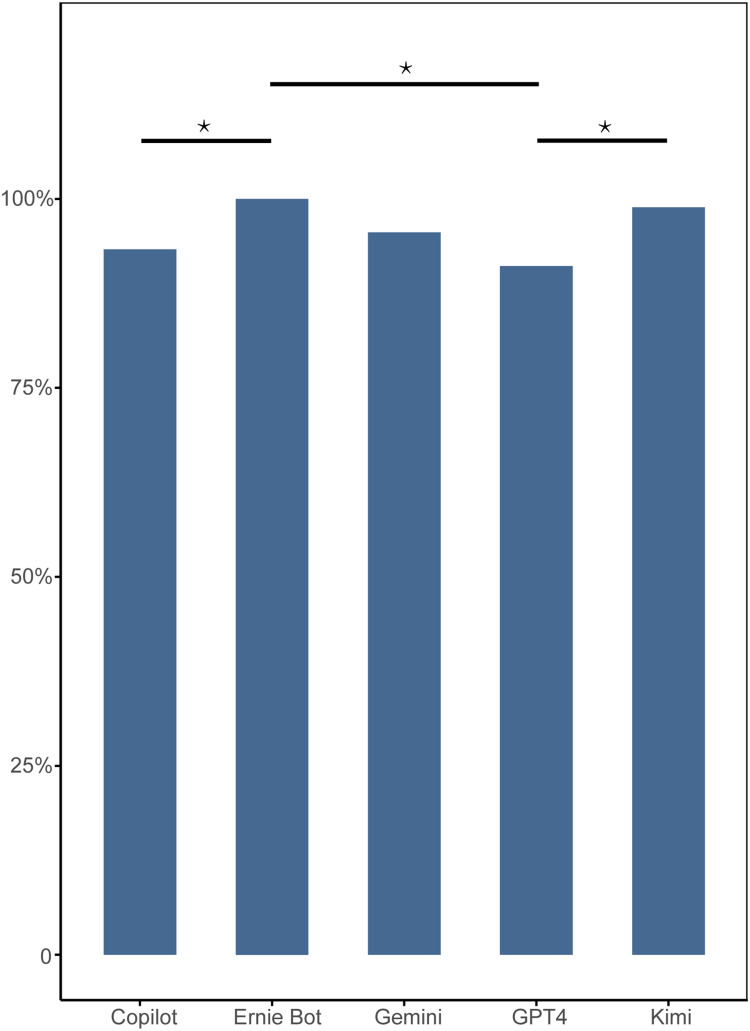
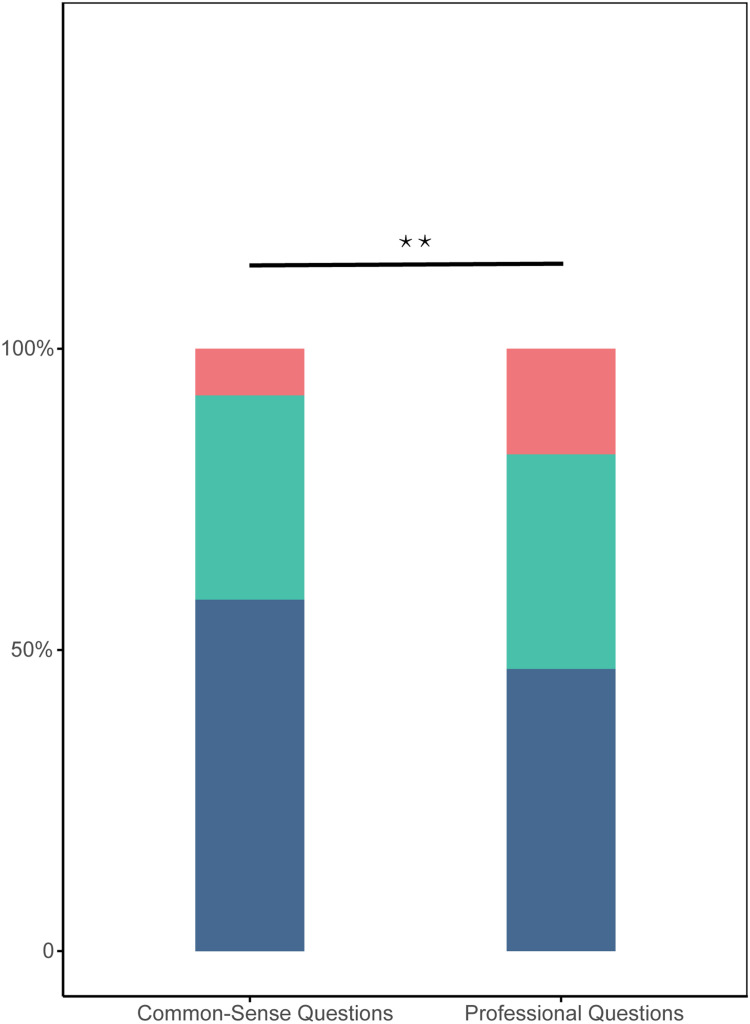
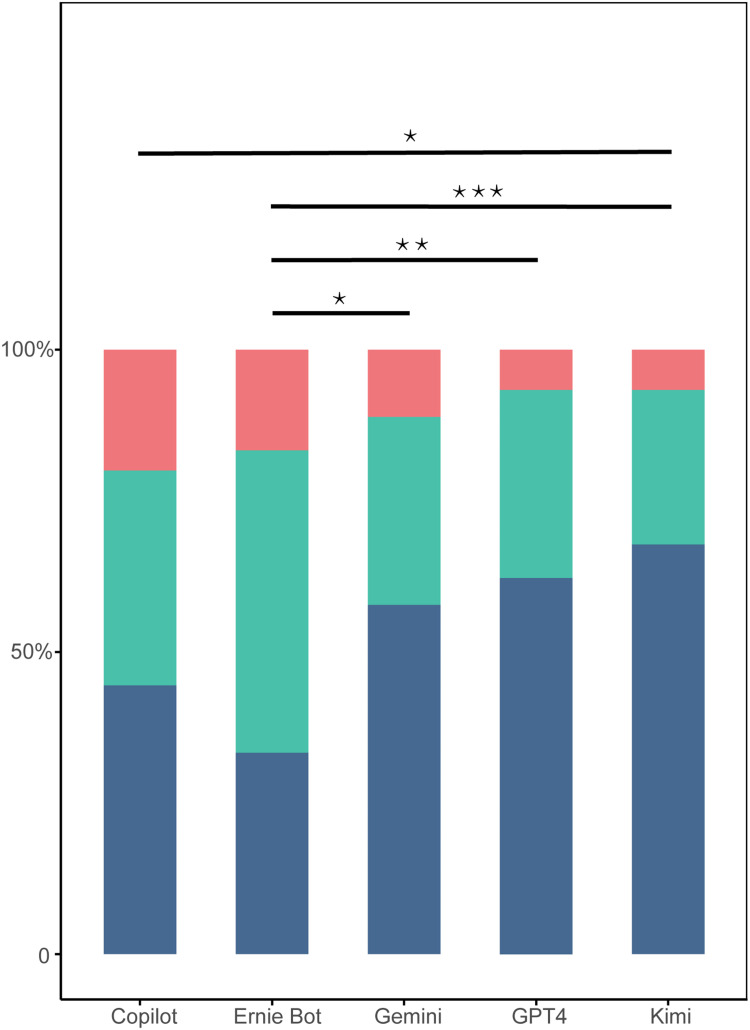
Results: Kimi and GPT-4 achieved the highest proportions of fully applicable responses (68% and 62%, respectively), while Ernie Bot and Copilot showed the lowest. Comprehensibility was generally high, with Kimi and Ernie Bot scoring over 98%. However, none of the LLMs consistently provided guideline-concordant answers to all questions. Performance on professional-level questions was significantly lower than on common-sense ones, highlighting deficiencies in complex clinical reasoning.
Conclusion: LLMs demonstrate varied performance in liver cancer-related queries. While GPT-4 and Kimi show promise in clinical applicability, limitations in accuracy and consistency-particularly for complex medical decisions-underscore the need for domain-specific optimization before clinical integration.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


