{"title":"UnCOT-AD: Unpaired Cross-Omics Translation Enables Multi-Omics Integration for Alzheimer's Disease Prediction.","authors":"Abrar Rahman Abir, Sajib Acharjee Dip, Liqing Zhang","doi":"10.1093/bib/bbaf438","DOIUrl":null,"url":null,"abstract":"<p><p>Alzheimer's Disease (AD) is a progressive neurodegenerative disorder, posing a growing public health challenge. Traditional machine learning models for AD prediction have relied on single omics data or phenotypic assessments, limiting their ability to capture the disease's molecular complexity and resulting in poor performance. Recent advances in high-throughput multi-omics have provided deeper biological insights. However, due to the scarcity of paired omics datasets, existing multi-omics AD prediction models rely on unpaired omics data, where different omics profiles are combined without being derived from the same biological sample, leading to biologically less meaningful pairings and causing less accurate predictions. To address these issues, we propose UnCOT-AD, a novel deep learning framework for Unpaired Cross-Omics Translation enabling effective multi-omics integration for AD prediction. Our method introduces the first-ever cross-omics translation model trained on unpaired omics datasets, using two coupled Variational Autoencoders and a novel cycle consistency mechanism to ensure accurate bidirectional translation between omics types. We integrate adversarial training to ensure that the generated omics profiles are biologically realistic. Moreover, we employ contrastive learning to capture the disease specific patterns in latent space to make the cross-omics translation more accurate and biologically relevant. We rigorously validate UnCOT-AD on both cross-omics translation and AD prediction tasks. Results show that UnCOT-AD empowers multi-omics based AD prediction by combining real omics profiles with corresponding omics profiles generated by our cross-omics translation module and achieves state-of-the-art performance in accuracy and robustness. Source code is available at https://github.com/abrarrahmanabir/UnCOT-AD.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"26 4","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2025-07-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12381766/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbaf438","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
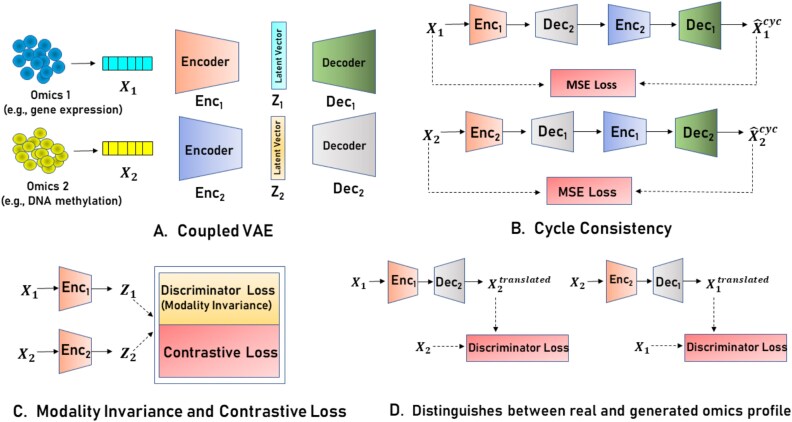
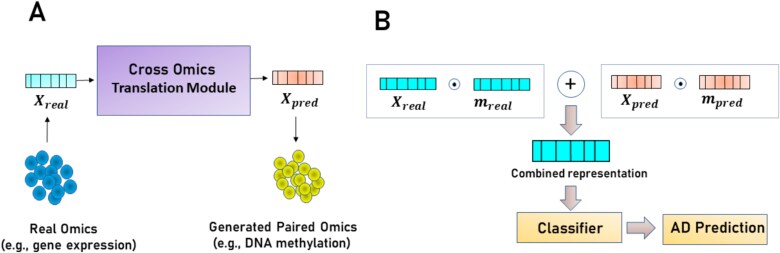
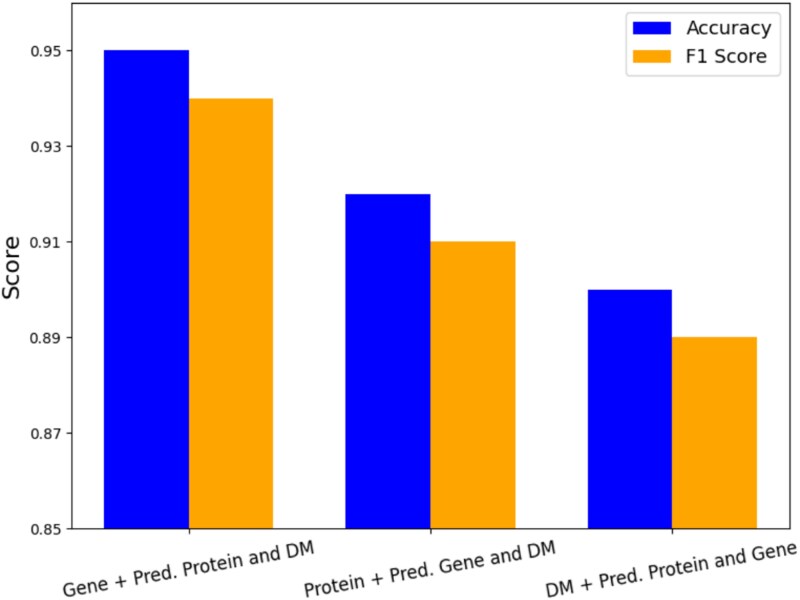
Alzheimer's Disease (AD) is a progressive neurodegenerative disorder, posing a growing public health challenge. Traditional machine learning models for AD prediction have relied on single omics data or phenotypic assessments, limiting their ability to capture the disease's molecular complexity and resulting in poor performance. Recent advances in high-throughput multi-omics have provided deeper biological insights. However, due to the scarcity of paired omics datasets, existing multi-omics AD prediction models rely on unpaired omics data, where different omics profiles are combined without being derived from the same biological sample, leading to biologically less meaningful pairings and causing less accurate predictions. To address these issues, we propose UnCOT-AD, a novel deep learning framework for Unpaired Cross-Omics Translation enabling effective multi-omics integration for AD prediction. Our method introduces the first-ever cross-omics translation model trained on unpaired omics datasets, using two coupled Variational Autoencoders and a novel cycle consistency mechanism to ensure accurate bidirectional translation between omics types. We integrate adversarial training to ensure that the generated omics profiles are biologically realistic. Moreover, we employ contrastive learning to capture the disease specific patterns in latent space to make the cross-omics translation more accurate and biologically relevant. We rigorously validate UnCOT-AD on both cross-omics translation and AD prediction tasks. Results show that UnCOT-AD empowers multi-omics based AD prediction by combining real omics profiles with corresponding omics profiles generated by our cross-omics translation module and achieves state-of-the-art performance in accuracy and robustness. Source code is available at https://github.com/abrarrahmanabir/UnCOT-AD.
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


