{"title":"<i>In Silico</i> Separation of <i>in Vitro</i> Transcription-Derived Duplicates From PCR Duplicates to Enhance Sequence Data Utilization.","authors":"Ryoga Suzuki, Kenichi Horisawa, Kazumitsu Maehara, Yasuyuki Ohkawa, Atsushi Suzuki","doi":"10.1177/11779322251365042","DOIUrl":null,"url":null,"abstract":"<p><p>The polymerase chain reaction (PCR) amplification process of deoxyribonucleic acid (DNA) libraries can introduce bias in the sequence ratios. Consequently, several recent genomic and transcriptomic methods employing next-generation sequencing (NGS) utilize <i>in vitro</i> transcription (IVT) to amplify template polynucleotide chains. IVT amplifies nucleic acid sequences linearly, making it less susceptible to bias than the exponential amplification of PCR. Chromatin integration labeling sequencing (ChIL-seq), a tool for analyzing transcription factor binding and histone modifications, has incorporated IVT by replacing PCR in the DNA amplification step, enabling the analysis of small sample sizes, including single cells. In this study, we discovered that many of the excluded sequences known as PCR duplicates during the pre-processing step of ChIL-seq data analysis contain amplification products derived from IVT. Furthermore, we developed an <i>in silico</i> method to selectively eliminate PCR duplicates from NGS data while retaining IVT-derived amplification products. The method prevents excessive data reduction and significantly improves the utilization efficiency of NGS data.</p>","PeriodicalId":9065,"journal":{"name":"Bioinformatics and Biology Insights","volume":"19 ","pages":"11779322251365042"},"PeriodicalIF":2.4000,"publicationDate":"2025-08-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12381453/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics and Biology Insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/11779322251365042","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
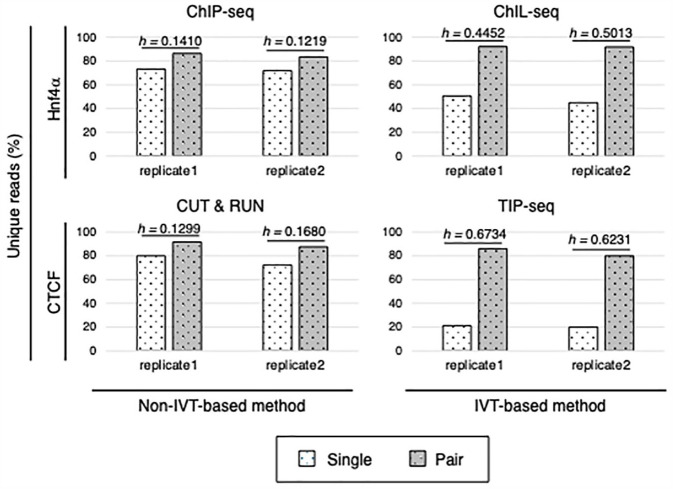
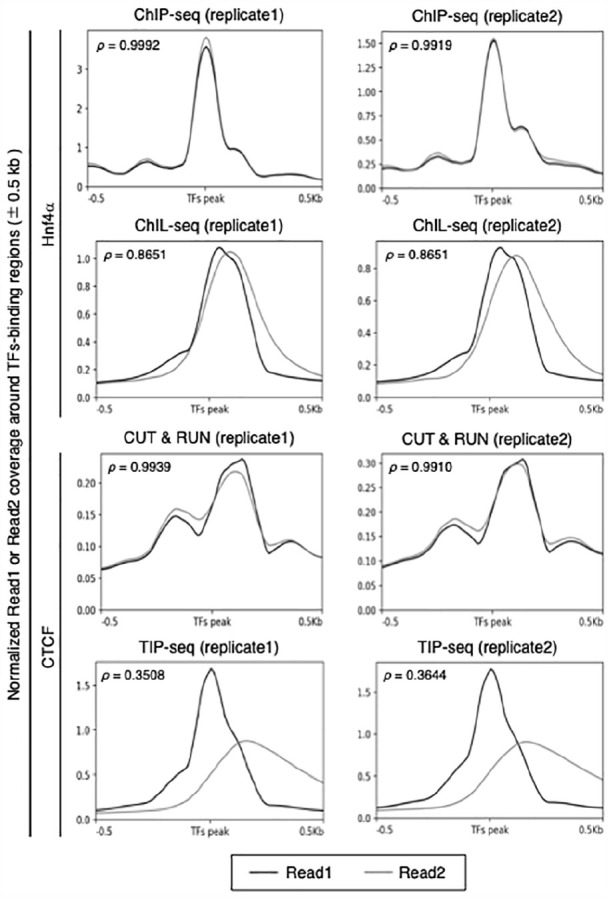
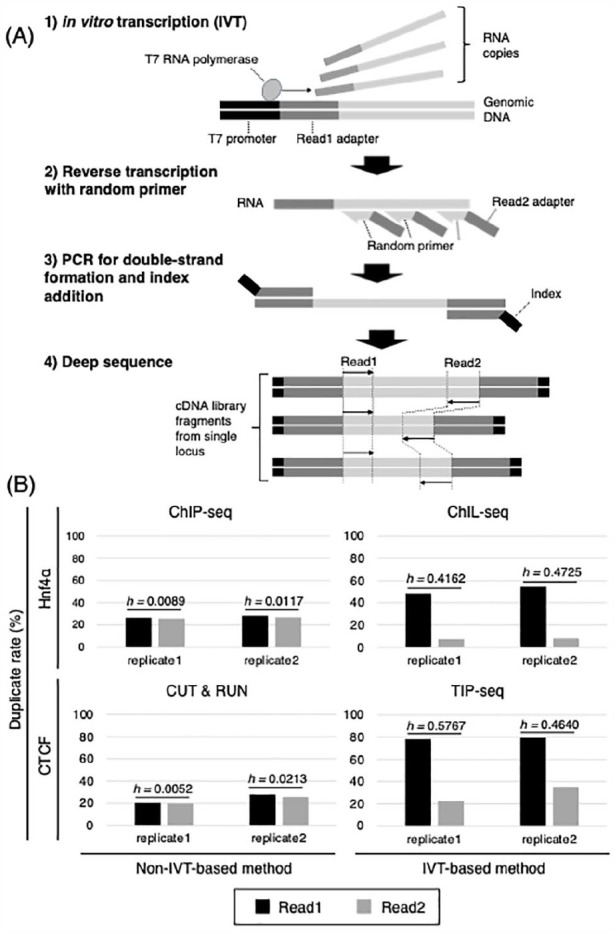
The polymerase chain reaction (PCR) amplification process of deoxyribonucleic acid (DNA) libraries can introduce bias in the sequence ratios. Consequently, several recent genomic and transcriptomic methods employing next-generation sequencing (NGS) utilize in vitro transcription (IVT) to amplify template polynucleotide chains. IVT amplifies nucleic acid sequences linearly, making it less susceptible to bias than the exponential amplification of PCR. Chromatin integration labeling sequencing (ChIL-seq), a tool for analyzing transcription factor binding and histone modifications, has incorporated IVT by replacing PCR in the DNA amplification step, enabling the analysis of small sample sizes, including single cells. In this study, we discovered that many of the excluded sequences known as PCR duplicates during the pre-processing step of ChIL-seq data analysis contain amplification products derived from IVT. Furthermore, we developed an in silico method to selectively eliminate PCR duplicates from NGS data while retaining IVT-derived amplification products. The method prevents excessive data reduction and significantly improves the utilization efficiency of NGS data.
期刊介绍:
Bioinformatics and Biology Insights is an open access, peer-reviewed journal that considers articles on bioinformatics methods and their applications which must pertain to biological insights. All papers should be easily amenable to biologists and as such help bridge the gap between theories and applications.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


