TPWGAN: Wavelet-aware text prior guided super-resolution for scene text images
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Scene text image super-resolution (STISR) is crucial for improving the readability and recognition accuracy of low-resolution text images. Many previous methods have incorporated text prior information, such as character sequences or recognition features, into super-resolution frameworks. However, existing methods struggle to recover fine-grained text structures, often introducing artifacts or blurry edges due to insufficient high-frequency (HF) modeling and suboptimal use of text priors. Although some recent approaches incorporate wavelet-domain losses into the generator, they typically retain RGB-domain losses during adversarial training, limiting their ability to distinguish authentic text details from artifacts. To address this, we propose TPWGAN, a GAN-based STISR framework that introduces wavelet-domain losses in both the generator and discriminator. The generator is trained with fidelity losses on the HF wavelet subbands to enhance sensitivity to stroke-level variations, while the discriminator processes HF wavelet subbands fused with binary text region masks via a spatial attention mechanism, enabling semantically guided frequency-aware discrimination. Experiments on the TextZoom dataset and several real-world benchmarks show that TPWGAN achieves consistent improvements in visual quality and text recognition, particularly for challenging text instances with distortions or low resolution.
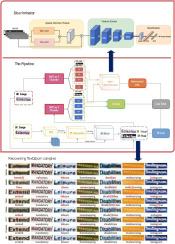
TPWGAN:小波感知文本先验引导的场景文本图像超分辨率
场景文本图像超分辨率(STISR)是提高低分辨率文本图像可读性和识别精度的关键。以前的许多方法都将文本先验信息(如字符序列或识别特征)纳入超分辨率框架中。然而,现有的方法很难恢复细粒度的文本结构,由于高频(HF)建模不足和文本先验的次优使用,通常会引入伪像或模糊的边缘。尽管最近的一些方法将小波域损失合并到生成器中,但它们通常在对抗训练期间保留rgb域损失,限制了它们区分真实文本细节和伪文本的能力。为了解决这个问题,我们提出了TPWGAN,这是一种基于gan的stir框架,它在发生器和鉴别器中都引入了小波域损失。发生器在高频小波子带上进行保真度损失训练,以提高对笔划水平变化的灵敏度,而鉴别器通过空间注意机制处理与二进制文本区域掩模融合的高频小波子带,实现语义引导的频率感知鉴别。在TextZoom数据集和几个现实世界基准测试上的实验表明,TPWGAN在视觉质量和文本识别方面取得了一致的改进,特别是对于具有扭曲或低分辨率的挑战性文本实例。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


