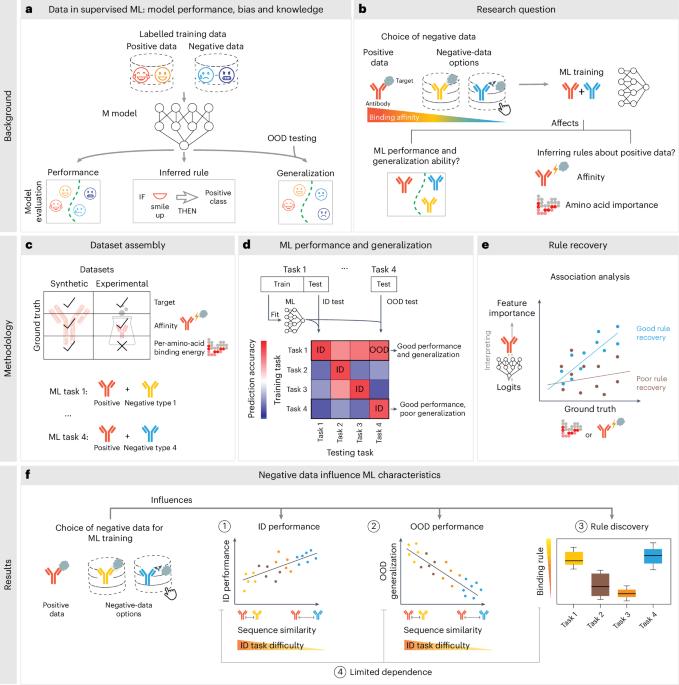
Training data composition determines machine learning generalization and biological rule discovery
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Supervised machine learning models depend on training datasets containing positive and negative examples: dataset composition directly impacts model performance and bias. Given the importance of machine learning for immunotherapeutic design, we examined how different negative class definitions affect model generalization and rule discovery for antibody–antigen binding. Using synthetic-structure-based binding data, we evaluated models trained with various definitions of negative sets. Our findings reveal that high out-of-distribution performance can be achieved when the negative dataset contains more similar samples to the positive dataset, despite lower in-distribution performance. Furthermore, by leveraging ground-truth information, we show that binding rules associated with positive data change based on the negative data used. Validation on experimental data supported simulation-based observations. This work underscores the role of dataset composition in creating robust, generalizable and biology-aware sequence-based ML models. Negative data composition critically shapes machine learning robustness in sequence-based biological tasks. Training data composition and its implications are investigated on biological rule discoveries.
训练数据的组成决定了机器学习的泛化和生物规则的发现
监督式机器学习模型依赖于包含正例和负例的训练数据集:数据集的组成直接影响模型的性能和偏差。鉴于机器学习对免疫治疗设计的重要性,我们研究了不同的负类定义如何影响抗体-抗原结合的模型泛化和规则发现。使用基于合成结构的绑定数据,我们评估了用各种负集定义训练的模型。我们的研究结果表明,尽管分布内性能较低,但当负数据集包含更多与正数据集相似的样本时,可以实现高的分布外性能。此外,通过利用真实信息,我们表明与正数据相关的绑定规则会根据所使用的负数据而变化。实验数据验证支持基于模拟的观察。这项工作强调了数据集组合在创建健壮、可推广和基于生物感知序列的ML模型中的作用。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


