Using large language models for solving textbook-style thermodynamic problems
IF 3.9
2区 工程技术
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
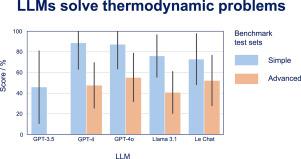
Large Language Models (LLMs) have made significant progress in reasoning, demonstrating their capability to generate human-like responses. This study analyzes the problem-solving capabilities of LLMs in the domain of thermodynamics. A benchmark of 22 textbook-style thermodynamic problems to evaluate LLMs is presented that contains both simple and advanced problems. Five different LLMs are assessed: GPT-3.5, GPT-4, and GPT-4o from OpenAI, Llama 3.1 from Meta, and le Chat from MistralAI. The answers of these LLMs were evaluated by trained human experts, following a methodology akin to the grading of academic exam responses. The scores and the consistency of the answers are discussed, together with the analytical skills of the LLMs. Both strengths and weaknesses of the LLMs become evident. They generally yield good results for the simple problems, but also limitations become clear: The LLMs do not provide consistent results, they often fail to fully comprehend the context and make wrong assumptions. Given the complexity and domain-specific nature of the problems, the statistical language modeling approach of the LLMs struggles with the accurate interpretation and the required reasoning. The present results highlight the need for more systematic integration of thermodynamic knowledge with LLMs, for example, by using knowledge-based methods.
使用大型语言模型来解决教科书式的热力学问题
大型语言模型(llm)在推理方面取得了重大进展,展示了它们产生类似人类反应的能力。本研究分析了热力学领域法学硕士解决问题的能力。提出了一个包含22个教科书式热力学问题的基准,以评估法学硕士,其中包括简单和高级问题。评估了五种不同的llm: OpenAI的GPT-3.5、GPT-4和gpt - 40, Meta的Llama 3.1和MistralAI的le Chat。这些法学硕士的答案由训练有素的人类专家评估,采用类似于学术考试评分的方法。讨论了分数和答案的一致性,以及法学硕士的分析技能。法学硕士的优势和劣势都变得显而易见。它们通常会对简单的问题产生好的结果,但也有明显的局限性:法学硕士不能提供一致的结果,它们经常不能完全理解上下文并做出错误的假设。考虑到问题的复杂性和特定领域的性质,法学硕士的统计语言建模方法与准确的解释和所需的推理作斗争。目前的结果强调需要更系统地整合热力学知识与法学硕士,例如,通过使用基于知识的方法。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Computers & Chemical Engineering
工程技术-工程:化工
CiteScore
8.70
自引率
14.00%
发文量
374
审稿时长
70 days
期刊介绍:
Computers & Chemical Engineering is primarily a journal of record for new developments in the application of computing and systems technology to chemical engineering problems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


