Multimodal video summarization based on graph contrastive learning with fine-grained graph interaction
IF 3.6
2区 工程技术
Q2 ENGINEERING, ELECTRICAL & ELECTRONIC
引用次数: 0
Abstract
Video summarization aims to extract key information from videos and select concise and representative clips to form a summary. However, unimodal video summarization methods have difficulty capturing the rich semantic in videos, while existing multimodal methods often face interference from redundant frames and noise during modal fusion, resulting in insufficient cross-modal interaction. Therefore, we introduce a multimodal video summarization model based on graph contrastive learning and fine-grained graph interaction. The model first constructs the video and text as graph structures, and uses a spatial–temporal graph network to collaboratively model spatial–temporal dependencies. Second, the node features of the video and text graph are optimized using graph contrastive learning to eliminate redundant frames and noise. In the cross-modal graph matching, the similarity between the video and text graph is modeled in parallel by introducing multiple semantic perspectives to achieve fine-grained cross-modal interaction. In addition, this paper introduces a graph alignment loss to further constrain the consistency of cross-modal semantic alignment. Finally, extensive experiments on two benchmark datasets, TVSum and SumMe, verify the effectiveness of the DCGM model, which outperforms the current state-of-the-art methods in terms of performance.
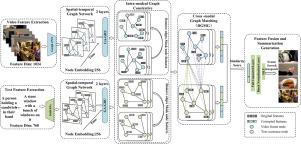
基于图对比学习和细粒度图交互的多模态视频摘要
视频摘要的目的是从视频中提取关键信息,选取简洁、有代表性的片段形成摘要。然而,单模态视频摘要方法难以捕获视频中丰富的语义,而现有的多模态方法在模态融合过程中经常受到冗余帧和噪声的干扰,导致跨模态交互不足。为此,我们提出了一种基于图对比学习和细粒度图交互的多模态视频摘要模型。该模型首先将视频和文本构建为图结构,并利用时空图网络对时空依赖关系进行协同建模。其次,利用图对比学习优化视频图和文本图的节点特征,消除冗余帧和噪声;在跨模态图匹配中,通过引入多个语义透视图,对视频图和文本图的相似度进行并行建模,实现细粒度的跨模态交互。此外,本文还引入了图对齐损失来进一步约束跨模态语义对齐的一致性。最后,在TVSum和SumMe两个基准数据集上进行了大量实验,验证了DCGM模型的有效性,该模型在性能方面优于当前最先进的方法。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Signal Processing
工程技术-工程:电子与电气
CiteScore
9.20
自引率
9.10%
发文量
309
审稿时长
41 days
期刊介绍:
Signal Processing incorporates all aspects of the theory and practice of signal processing. It features original research work, tutorial and review articles, and accounts of practical developments. It is intended for a rapid dissemination of knowledge and experience to engineers and scientists working in the research, development or practical application of signal processing.
Subject areas covered by the journal include: Signal Theory; Stochastic Processes; Detection and Estimation; Spectral Analysis; Filtering; Signal Processing Systems; Software Developments; Image Processing; Pattern Recognition; Optical Signal Processing; Digital Signal Processing; Multi-dimensional Signal Processing; Communication Signal Processing; Biomedical Signal Processing; Geophysical and Astrophysical Signal Processing; Earth Resources Signal Processing; Acoustic and Vibration Signal Processing; Data Processing; Remote Sensing; Signal Processing Technology; Radar Signal Processing; Sonar Signal Processing; Industrial Applications; New Applications.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


