Exploring the robustness of TractOracle methods in RL-based tractography
IF 11.8
1区 医学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Tractography algorithms leverage diffusion MRI to reconstruct the fibrous architecture of the brain’s white matter. Among machine learning approaches, reinforcement learning (RL) has emerged as a promising framework for tractography, outperforming traditional methods in several key aspects. TractOracle-RL, a recent RL-based approach, reduces false positives by incorporating anatomical priors into the training process via a reward-based mechanism.
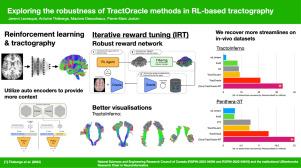
In this paper, we investigate four extensions of the original TractOracle-RL framework by integrating recent advances in RL, and we evaluate their performance across five diverse diffusion MRI datasets. Results demonstrate that combining an oracle with the RL framework consistently leads to robust and reliable tractography, regardless of the specific method or dataset used.
We also introduce a novel RL training scheme called Iterative Reward Training (IRT), inspired by the Reinforcement Learning from Human Feedback (RLHF) paradigm. Instead of relying on human input, IRT leverages bundle filtering methods to iteratively refine the oracle’s guidance throughout training. Experimental results show that RL methods trained with oracle feedback significantly outperform widely used tractography techniques in terms of accuracy and anatomical validity.

探索基于rl的TractOracle方法的鲁棒性
神经束造影算法利用弥散MRI重建大脑白质的纤维结构。在机器学习方法中,强化学习(RL)已成为一种有前途的神经束成像框架,在几个关键方面优于传统方法。TractOracle-RL是最近一种基于rl的方法,通过基于奖励的机制将解剖学先验纳入训练过程,从而减少误报。在本文中,我们通过整合RL的最新进展,研究了原始TractOracle-RL框架的四种扩展,并在五种不同的扩散MRI数据集上评估了它们的性能。结果表明,无论使用何种具体方法或数据集,将oracle与RL框架相结合始终会产生稳健可靠的轨迹图。我们还介绍了一种新的强化学习训练方案,称为迭代奖励训练(IRT),灵感来自人类反馈的强化学习(RLHF)范式。IRT不依赖于人工输入,而是利用包过滤方法在整个训练过程中迭代地改进oracle的指导。实验结果表明,经oracle反馈训练的RL方法在准确性和解剖学有效性方面明显优于广泛使用的神经束造影技术。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Medical image analysis
工程技术-工程:生物医学
CiteScore
22.10
自引率
6.40%
发文量
309
审稿时长
6.6 months
期刊介绍:
Medical Image Analysis serves as a platform for sharing new research findings in the realm of medical and biological image analysis, with a focus on applications of computer vision, virtual reality, and robotics to biomedical imaging challenges. The journal prioritizes the publication of high-quality, original papers contributing to the fundamental science of processing, analyzing, and utilizing medical and biological images. It welcomes approaches utilizing biomedical image datasets across all spatial scales, from molecular/cellular imaging to tissue/organ imaging.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


