Ahmed Abdelmotteleb, Alessandro Bertolin, Chris Burr, Ben Couturier, Ellinor Eckstein, Davide Fazzini, Nathan Grieser, Christophe Haen, Ryunosuke O'Neil, Eduardo Rodrigues, Nicole Skidmore, Mark Smith, Aidan R Wiederhold, Shunan Zhang
{"title":"The LHCb Sprucing and Analysis Productions.","authors":"Ahmed Abdelmotteleb, Alessandro Bertolin, Chris Burr, Ben Couturier, Ellinor Eckstein, Davide Fazzini, Nathan Grieser, Christophe Haen, Ryunosuke O'Neil, Eduardo Rodrigues, Nicole Skidmore, Mark Smith, Aidan R Wiederhold, Shunan Zhang","doi":"10.1007/s41781-025-00144-5","DOIUrl":null,"url":null,"abstract":"<p><p>The LHCb detector underwent a comprehensive upgrade in preparation for the third data-taking run of the Large Hadron Collider (LHC), known as LHCb Upgrade I. With its increased data rate, Run 3 introduced considerable challenges in both data acquisition (online) and data processing and analysis (offline). The offline processing and analysis model was upgraded to handle the factor 30 increase in data volume and the associated demands of ever-growing datasets for analysis, led by the LHCb Data Processing and Analysis (DPA) project. This paper documents the LHCb \"Sprucing\" - the centralised offline data processing and selections - and \"Analysis Productions\" - the centralised and highly automated declarative nTuple production system. The DaVinci application used by analysis productions for tupling spruced data is described as well as the apd and lbconda tools for data retrieval and analysis environment configuration. These tools allow for greatly improved analyst workflows and analysis preservation. Finally, the approach to data processing and analysis in the High-Luminosity Large Hadron Collider (HL-LHC) era - LHCb Upgrade II - is discussed.</p>","PeriodicalId":36026,"journal":{"name":"Computing and Software for Big Science","volume":"9 1","pages":"15"},"PeriodicalIF":0.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12321665/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computing and Software for Big Science","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s41781-025-00144-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/4 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
引用次数: 0
Abstract
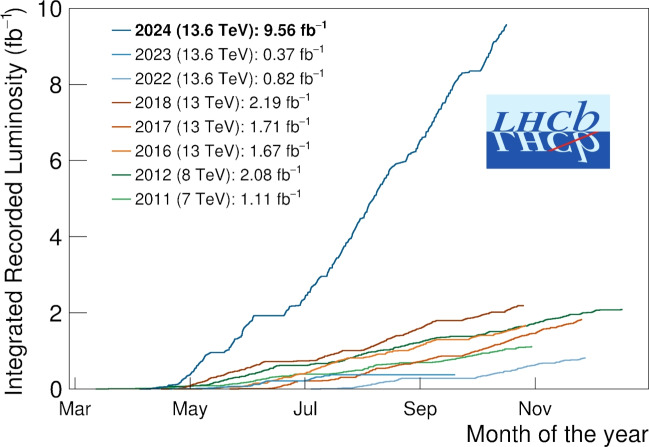
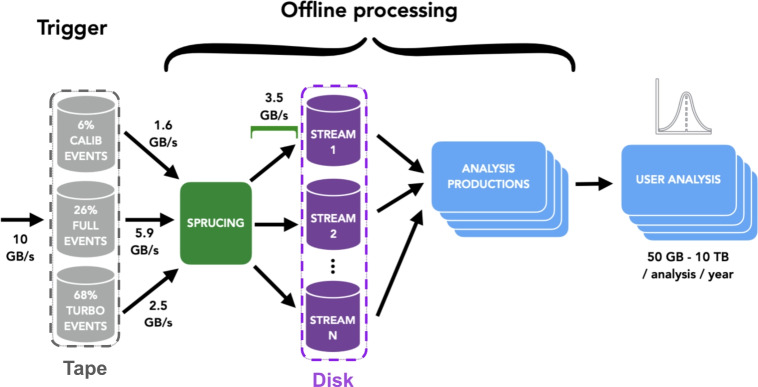
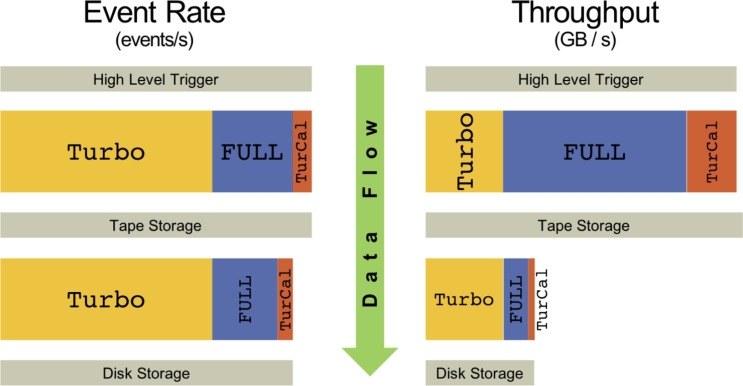
The LHCb detector underwent a comprehensive upgrade in preparation for the third data-taking run of the Large Hadron Collider (LHC), known as LHCb Upgrade I. With its increased data rate, Run 3 introduced considerable challenges in both data acquisition (online) and data processing and analysis (offline). The offline processing and analysis model was upgraded to handle the factor 30 increase in data volume and the associated demands of ever-growing datasets for analysis, led by the LHCb Data Processing and Analysis (DPA) project. This paper documents the LHCb "Sprucing" - the centralised offline data processing and selections - and "Analysis Productions" - the centralised and highly automated declarative nTuple production system. The DaVinci application used by analysis productions for tupling spruced data is described as well as the apd and lbconda tools for data retrieval and analysis environment configuration. These tools allow for greatly improved analyst workflows and analysis preservation. Finally, the approach to data processing and analysis in the High-Luminosity Large Hadron Collider (HL-LHC) era - LHCb Upgrade II - is discussed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


