Danilo Silva, Monika Moir, Marcel Dunaiski, Natalia Blanco, Fati Murtala-Ibrahim, Cheryl Baxter, Tulio de Oliveira, Joicymara S Xavier
{"title":"Review of open-source software for developing heterogeneous data management systems for bioinformatics applications.","authors":"Danilo Silva, Monika Moir, Marcel Dunaiski, Natalia Blanco, Fati Murtala-Ibrahim, Cheryl Baxter, Tulio de Oliveira, Joicymara S Xavier","doi":"10.1093/bioadv/vbaf168","DOIUrl":null,"url":null,"abstract":"<p><strong>Summary: </strong>In a world where data drive effective decision-making, bioinformatics and health science researchers often encounter difficulties managing data efficiently. In these fields, data are typically diverse in format and subject. Consequently, challenges in storing, tracking, and responsibly sharing valuable data have become increasingly evident over the past decades. To address the complexities, some approaches have leveraged standard strategies, such as using non-relational databases and data warehouses. However, these approaches often fall short in providing the flexibility and scalability required for complex projects. While the data lake paradigm has emerged to offer flexibility and handle large volumes of diverse data, it lacks robust data governance and organization. The data lakehouse is a new paradigm that combines the flexibility of a data lake with the governance of a data warehouse, offering a promising solution for managing heterogeneous data in bioinformatics. However, the lakehouse model remains unexplored in bioinformatics, with limited discussion in the current literature. In this study, we review strategies and tools for developing a data lakehouse infrastructure tailored to bioinformatics research. We summarize key concepts and assess available open-source and commercial solutions for managing data in bioinformatics.</p><p><strong>Availability and implementation: </strong>Not applicable.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf168"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12321290/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf168","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
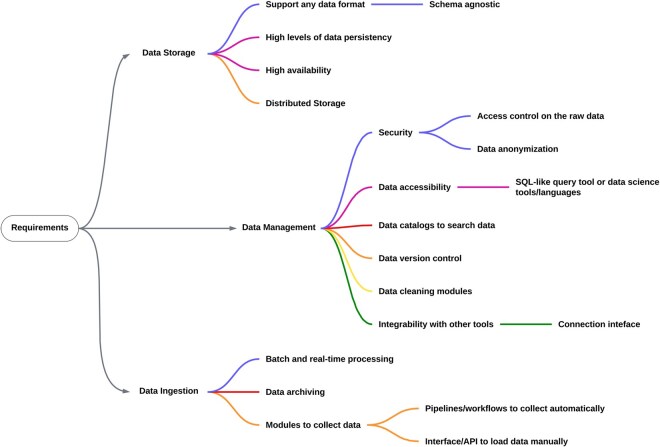
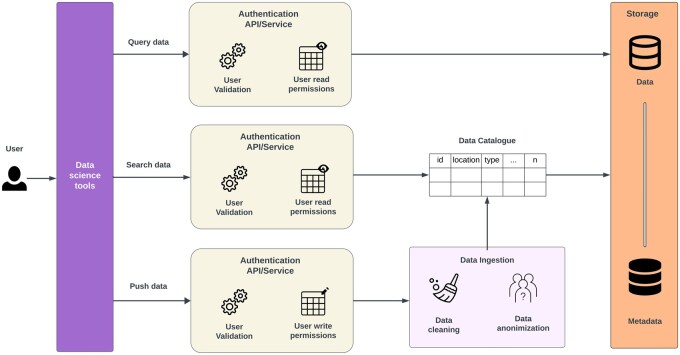
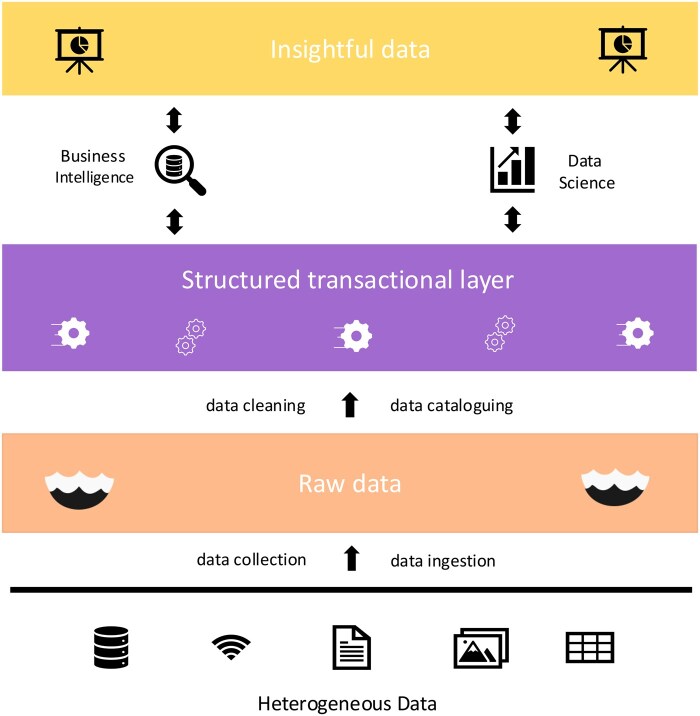
Summary: In a world where data drive effective decision-making, bioinformatics and health science researchers often encounter difficulties managing data efficiently. In these fields, data are typically diverse in format and subject. Consequently, challenges in storing, tracking, and responsibly sharing valuable data have become increasingly evident over the past decades. To address the complexities, some approaches have leveraged standard strategies, such as using non-relational databases and data warehouses. However, these approaches often fall short in providing the flexibility and scalability required for complex projects. While the data lake paradigm has emerged to offer flexibility and handle large volumes of diverse data, it lacks robust data governance and organization. The data lakehouse is a new paradigm that combines the flexibility of a data lake with the governance of a data warehouse, offering a promising solution for managing heterogeneous data in bioinformatics. However, the lakehouse model remains unexplored in bioinformatics, with limited discussion in the current literature. In this study, we review strategies and tools for developing a data lakehouse infrastructure tailored to bioinformatics research. We summarize key concepts and assess available open-source and commercial solutions for managing data in bioinformatics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


