Gadi Chaykin, Omer Sabary, Nili Furman, Dvir Ben Shabat, Eitan Yaakobi
{"title":"Dna-storalator: a computational simulator for DNA data storage.","authors":"Gadi Chaykin, Omer Sabary, Nili Furman, Dvir Ben Shabat, Eitan Yaakobi","doi":"10.1186/s12859-025-06222-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>DNA data storage is an emerging technology that caught the attention of many researchers and engineers. This technology uses DNA molecules as a storage medium and thus presents an extremely dense and durable storage device. However, the unique nature of the errors in DNA, which include insertion, deletion, and substitution errors, requires the development of new algorithmic and coding solutions for these storage systems.</p><p><strong>Results: </strong>The DNA-Storalator is a cross-platform software tool that simulates in a simplified digital point of view biological and computational processes involved in the process of storing data in DNA molecules. The simulator receives an input file with the designed DNA strands that store digital data and emulates the different biological and algorithmical components of DNA-based storage system. The biological component includes simulation of the synthesis, PCR, and sequencing stages which are expensive and complicated and therefore are not widely accessible to the community. These processes amplify the data and generate noisy copies of each DNA strand, where the errors are insertions, deletions, long-deletions, and substitutions. The DNA-Storalator injects errors to the data based on the error rates, as they vary between different synthesis and sequencing technologies. The rates are based on comprehensive analysis of data from previous experiments but can also be customized. Additionally, the tool can analyze new datasets and characterize their error rates to build new error models for future usage in the simulator. The DNA-Storalator also enables control of the amplification process and the distribution of the number of copies per designed strand. The coding and algorithmic components are: 1. Clustering algorithms which partition all output noisy strands into groups according to the designed strand they originated from; 2. State-of-the-art reconstruction algorithms that are invoked on each cluster to output a close/exact estimation of the designed strand; 3. Integration with external error-correcting codes and other encoding and decoding techniques.</p><p><strong>Conclusions: </strong>The suggested computational DNA storage simulator grants researchers from all fields an accessible complete simulator to examine new biological technologies, coding techniques, and algorithms for current and future DNA storage systems.</p>","PeriodicalId":8958,"journal":{"name":"BMC Bioinformatics","volume":"26 1","pages":"204"},"PeriodicalIF":3.3000,"publicationDate":"2025-08-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12323093/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s12859-025-06222-0","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: DNA data storage is an emerging technology that caught the attention of many researchers and engineers. This technology uses DNA molecules as a storage medium and thus presents an extremely dense and durable storage device. However, the unique nature of the errors in DNA, which include insertion, deletion, and substitution errors, requires the development of new algorithmic and coding solutions for these storage systems.
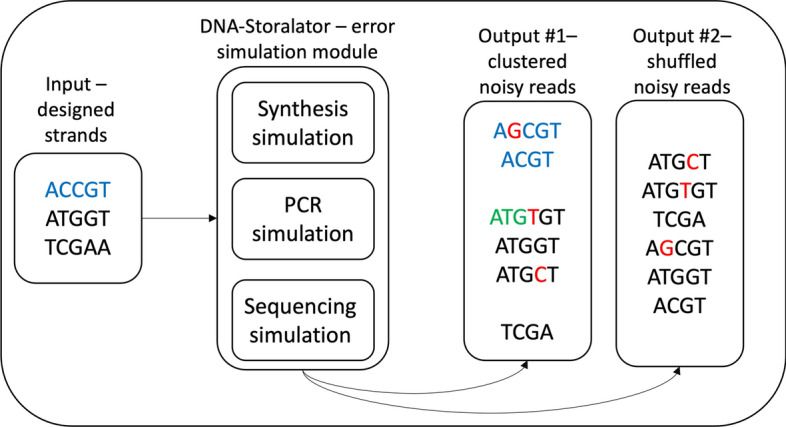
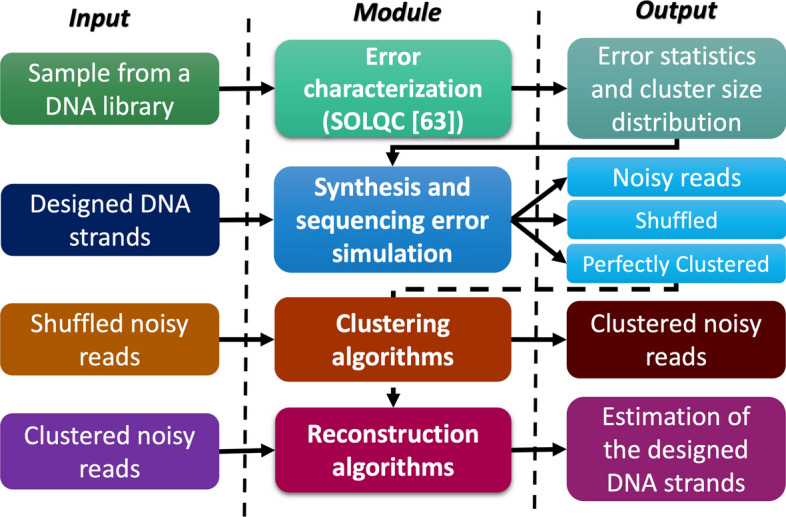
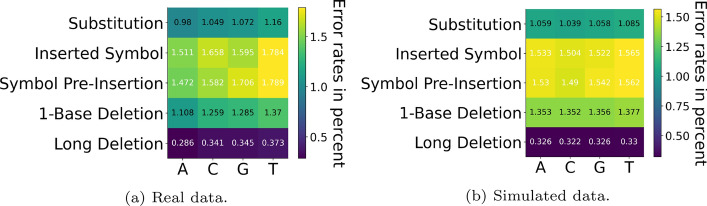
Results: The DNA-Storalator is a cross-platform software tool that simulates in a simplified digital point of view biological and computational processes involved in the process of storing data in DNA molecules. The simulator receives an input file with the designed DNA strands that store digital data and emulates the different biological and algorithmical components of DNA-based storage system. The biological component includes simulation of the synthesis, PCR, and sequencing stages which are expensive and complicated and therefore are not widely accessible to the community. These processes amplify the data and generate noisy copies of each DNA strand, where the errors are insertions, deletions, long-deletions, and substitutions. The DNA-Storalator injects errors to the data based on the error rates, as they vary between different synthesis and sequencing technologies. The rates are based on comprehensive analysis of data from previous experiments but can also be customized. Additionally, the tool can analyze new datasets and characterize their error rates to build new error models for future usage in the simulator. The DNA-Storalator also enables control of the amplification process and the distribution of the number of copies per designed strand. The coding and algorithmic components are: 1. Clustering algorithms which partition all output noisy strands into groups according to the designed strand they originated from; 2. State-of-the-art reconstruction algorithms that are invoked on each cluster to output a close/exact estimation of the designed strand; 3. Integration with external error-correcting codes and other encoding and decoding techniques.
Conclusions: The suggested computational DNA storage simulator grants researchers from all fields an accessible complete simulator to examine new biological technologies, coding techniques, and algorithms for current and future DNA storage systems.
期刊介绍:
BMC Bioinformatics is an open access, peer-reviewed journal that considers articles on all aspects of the development, testing and novel application of computational and statistical methods for the modeling and analysis of all kinds of biological data, as well as other areas of computational biology.
BMC Bioinformatics is part of the BMC series which publishes subject-specific journals focused on the needs of individual research communities across all areas of biology and medicine. We offer an efficient, fair and friendly peer review service, and are committed to publishing all sound science, provided that there is some advance in knowledge presented by the work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


