Clara Shionyu-Mitusyama, Satoshi Ohmori, Subaru Hirata, Hirokazu Ishida, Tsuyoshi Shirai
{"title":"IDRdecoder: a machine learning approach for rational drug discovery toward intrinsically disordered regions.","authors":"Clara Shionyu-Mitusyama, Satoshi Ohmori, Subaru Hirata, Hirokazu Ishida, Tsuyoshi Shirai","doi":"10.3389/fbinf.2025.1627836","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Intrinsically disordered regions (IDRs) of proteins have traditionally been overlooked as drug targets. However, with growing recognition of their crucial role in biological activity and their involvement in various diseases, IDRs have emerged as promising targets for drug discovery. Despite this potential, rational methodologies for IDR-targeted drug discovery remain underdeveloped, primarily due to a lack of reference experimental data.</p><p><strong>Methods: </strong>This study explores a machine learning approach to predict IDR functions, drug interaction sites, and interacting molecular substructures within IDR sequences. To address the data gap, stepwise transfer learning was employed. IDRdecoder sequentially generate predictions for IDR classification, interaction sites, and interacting ligand substructures. In the first step, the neural net was trained as autoencoder by using 26,480,862 predicted IDR sequences. Then it was trained against 57,692 ligand-binding PDB sequences with higher IDR tendency via transfer learning for predict ligand interacting sites and ligand types.</p><p><strong>Results: </strong>IDRdecoder was evaluated against 9 IDR sequences, which were experimentally detailed as drug targets. In the encoding space, specific GO terms related to the hypothesized functions of the evaluation IDR sequences were highly enriched. The model's prediction performance for drug interacting sites and ligand types demonstrated the area under the curve (AUC) of 0.616 and 0.702, respectively. The performance was compared with existing methods including ProteinBERT, and IDRdecoder demonstrated moderately improved performance.</p><p><strong>Discussion: </strong>IDRdecoder is the first application for predicting drug interaction sites and ligands in IDR sequences. Analysis of the prediction results revealed characteristics beneficial for IDR-drug design; for instance, Tyr and Ala are preferred target sites, while flexible substructures, such as alkyl groups, are favored in ligand molecules.</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":"5 ","pages":"1627836"},"PeriodicalIF":3.9000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12313641/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2025.1627836","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Intrinsically disordered regions (IDRs) of proteins have traditionally been overlooked as drug targets. However, with growing recognition of their crucial role in biological activity and their involvement in various diseases, IDRs have emerged as promising targets for drug discovery. Despite this potential, rational methodologies for IDR-targeted drug discovery remain underdeveloped, primarily due to a lack of reference experimental data.
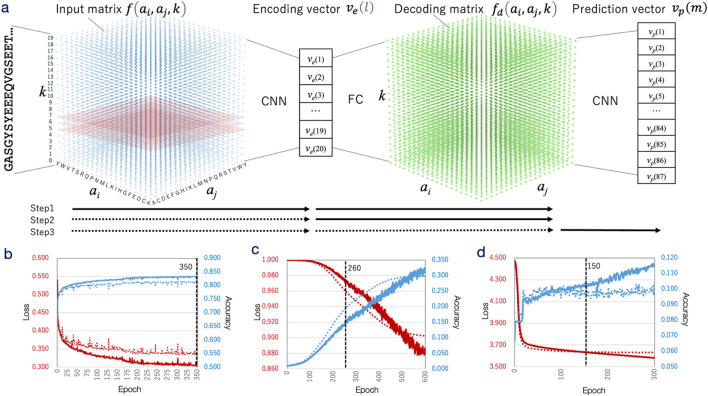
Methods: This study explores a machine learning approach to predict IDR functions, drug interaction sites, and interacting molecular substructures within IDR sequences. To address the data gap, stepwise transfer learning was employed. IDRdecoder sequentially generate predictions for IDR classification, interaction sites, and interacting ligand substructures. In the first step, the neural net was trained as autoencoder by using 26,480,862 predicted IDR sequences. Then it was trained against 57,692 ligand-binding PDB sequences with higher IDR tendency via transfer learning for predict ligand interacting sites and ligand types.
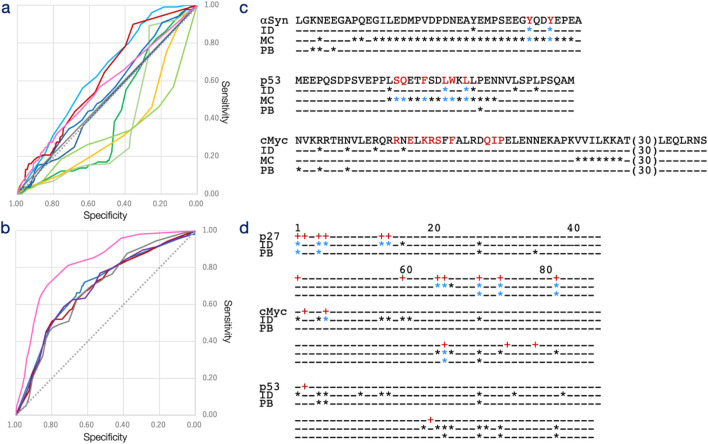
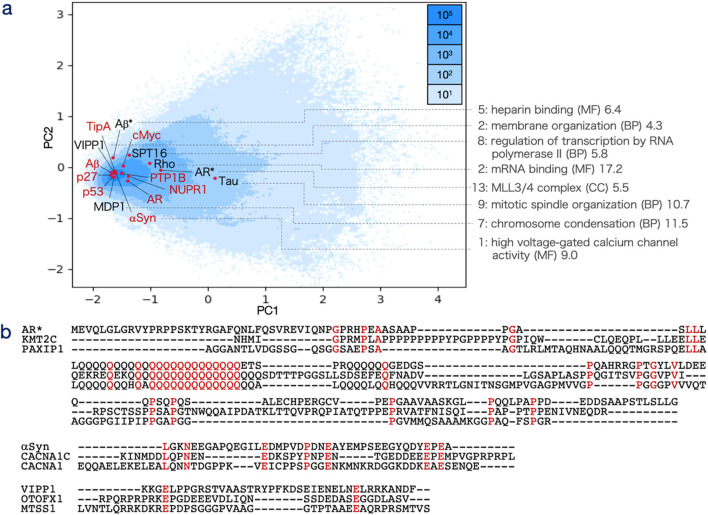
Results: IDRdecoder was evaluated against 9 IDR sequences, which were experimentally detailed as drug targets. In the encoding space, specific GO terms related to the hypothesized functions of the evaluation IDR sequences were highly enriched. The model's prediction performance for drug interacting sites and ligand types demonstrated the area under the curve (AUC) of 0.616 and 0.702, respectively. The performance was compared with existing methods including ProteinBERT, and IDRdecoder demonstrated moderately improved performance.
Discussion: IDRdecoder is the first application for predicting drug interaction sites and ligands in IDR sequences. Analysis of the prediction results revealed characteristics beneficial for IDR-drug design; for instance, Tyr and Ala are preferred target sites, while flexible substructures, such as alkyl groups, are favored in ligand molecules.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


