A semantic-enhanced multi-modal remote sensing foundation model for Earth observation
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
Remote sensing foundation models, pretrained on massive remote sensing data, have shown impressive performance in several Earth observation (EO) tasks. These models usually use single-modal temporal data for pretraining, which is insufficient for multi-modal applications. Moreover, these models require a considerable number of samples for fine-tuning in downstream tasks, posing challenges in time-sensitive scenarios, such as rapid flood mapping. We present SkySense++, a multi-modal remote sensing foundation model for diverse EO tasks. SkySense++ has a factorized architecture to accommodate multi-modal images acquired by diverse sensors. We adopt progressive pretraining, which involves two stages, on meticulously curated datasets of 27 million multi-modal remote sensing images. The first representation-enhanced pretraining stage uses multi-granularity contrastive learning to obtain general representations. The second semantic-enhanced pretraining stage leverages masked semantic learning to learn semantically enriched representations, enabling few-shot capabilities. This ability allows the model to handle unseen tasks with minimal labelled data, alleviating the need for fine-tuning on extensive annotated data. SkySense++ demonstrates consistent improvements in classification, detection and segmentation over previous state-of-the-art models across 12 EO tasks in 7 domains: agriculture, forestry, oceanography, atmosphere, biology, land surveying and disaster management. This generalizability may lead to a new chapter of remote sensing foundation model applications for EO tasks at scale. Wu et al. developed SkySense++, a multi-modal remote sensing foundation model pretrained on 27 million multi-modal images, which achieved robust generalization and few-shot capabilities across several Earth observation tasks and domains, including agriculture and disaster management.

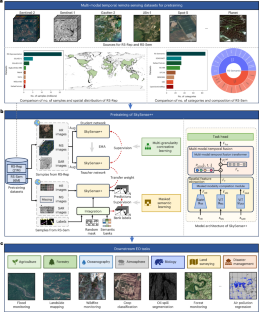
基于语义增强的多模态遥感对地观测基础模型
基于海量遥感数据进行预训练的遥感基础模型在若干对地观测任务中表现出令人印象深刻的性能。这些模型通常使用单模态时间数据进行预训练,这对于多模态应用来说是不够的。此外,这些模型需要大量的样本来进行下游任务的微调,这对时间敏感的场景(如快速洪水绘图)提出了挑战。我们提出了一个多模态遥感基础模型skysen++,用于各种EO任务。skysen++有一个分解的架构,以适应由不同的传感器获得的多模态图像。我们在精心整理的2700万多模态遥感图像数据集上采用了分两个阶段的渐进式预训练。第一个表征增强预训练阶段使用多粒度对比学习来获得一般表征。第二个语义增强的预训练阶段利用掩码语义学习来学习语义丰富的表示,从而实现少量射击功能。这种能力允许模型用最少的标记数据处理看不见的任务,减轻了对大量带注释的数据进行微调的需要。在农业、林业、海洋学、大气、生物学、土地测量和灾害管理等7个领域的12个EO任务中,skysen++在分类、检测和分割方面比以前最先进的模型有了持续的改进。这种通用性可能会为遥感基础模型在大规模EO任务中的应用开辟新的篇章。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


