Shipra Jain, Ritu Tomer, Sumeet Patiyal, Gajendra P S Raghava
{"title":"NfκBin: a machine learning based method for screening TNF-α induced NF-κB inhibitors.","authors":"Shipra Jain, Ritu Tomer, Sumeet Patiyal, Gajendra P S Raghava","doi":"10.3389/fbinf.2025.1573744","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Nuclear Factor kappa B (NF-κB) is a transcription factor whose upregulation is associated in chronic inflammatory diseases, including rheumatoid arthritis, inflammatory bowel disease, and asthma. In order to develop therapeutic strategies targeting NF-κB-related diseases, we developed a computational approach to predict drugs capable of inhibiting TNF-α induced NF-κB signaling pathways.</p><p><strong>Method: </strong>We utilized a dataset comprising 1,149 inhibitors and 1,332 non-inhibitors retrieved from PubChem. Chemical descriptors were computed using the PaDEL software, and relevant features were selected using advanced feature selection techniques.</p><p><strong>Result: </strong>Initially, machine learning models were constructed using 2D descriptors, 3D descriptors, and molecular fingerprints, achieving maximum AUC values of 0.66, 0.56, and 0.66, respectively. To improve feature selection, we applied univariate analysis and SVC-L1 regularization to identify features that can effectively differentiate inhibitors from non-inhibitors. Using these selected features, we developed machine learning models, our support vector classifier achieved a highest AUC of 0.75 on the validation dataset.</p><p><strong>Discussion: </strong>Finally, this best-performing model was employed to screen FDA-approved drugs for potential NF-κB inhibitors. Notably, most of the predicted inhibitors corresponded to drugs previously identified as inhibitors in experimental studies, underscoring the model's predictive reliability. Our best-performing models have been integrated into a standalone software and web server, NfκBin. (https://webs.iiitd.edu.in/raghava/nfkbin/).</p>","PeriodicalId":73066,"journal":{"name":"Frontiers in bioinformatics","volume":"5 ","pages":"1573744"},"PeriodicalIF":3.9000,"publicationDate":"2025-07-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12310657/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fbinf.2025.1573744","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
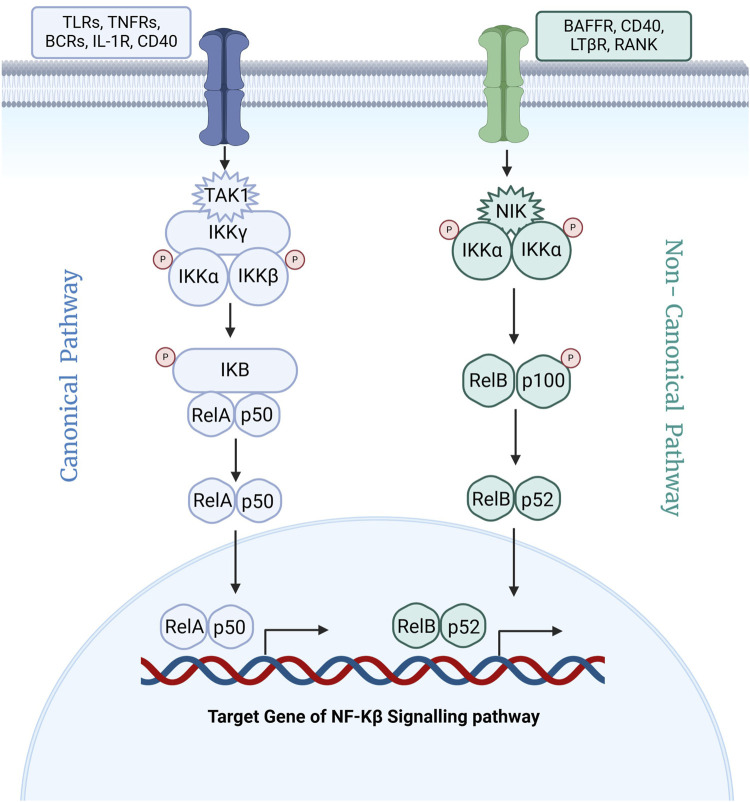
Introduction: Nuclear Factor kappa B (NF-κB) is a transcription factor whose upregulation is associated in chronic inflammatory diseases, including rheumatoid arthritis, inflammatory bowel disease, and asthma. In order to develop therapeutic strategies targeting NF-κB-related diseases, we developed a computational approach to predict drugs capable of inhibiting TNF-α induced NF-κB signaling pathways.
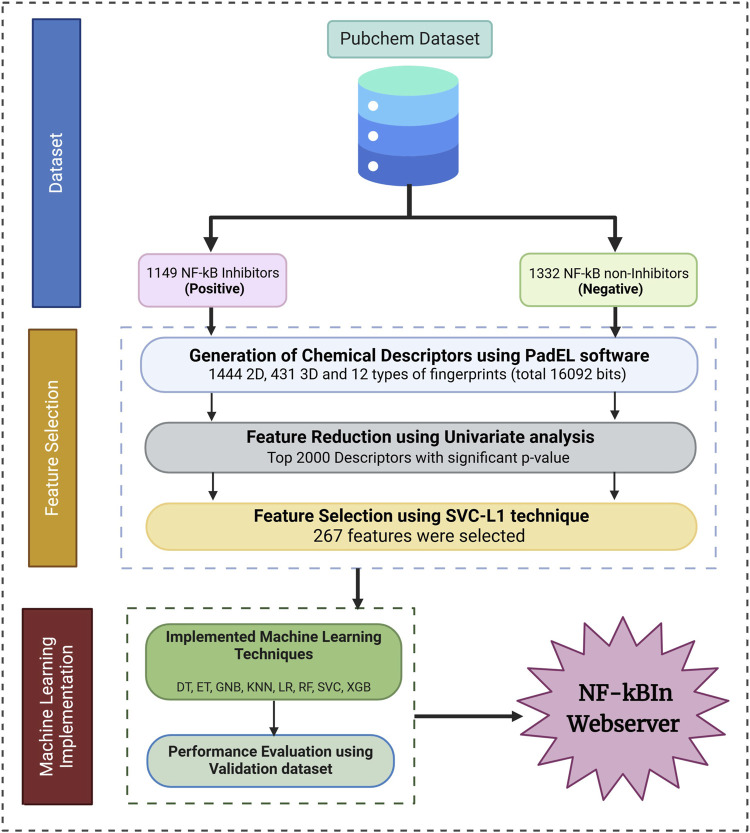
Method: We utilized a dataset comprising 1,149 inhibitors and 1,332 non-inhibitors retrieved from PubChem. Chemical descriptors were computed using the PaDEL software, and relevant features were selected using advanced feature selection techniques.
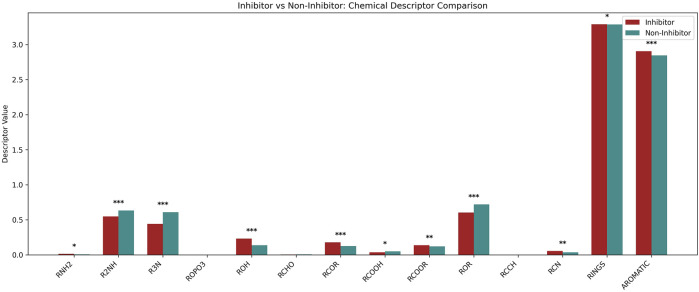
Result: Initially, machine learning models were constructed using 2D descriptors, 3D descriptors, and molecular fingerprints, achieving maximum AUC values of 0.66, 0.56, and 0.66, respectively. To improve feature selection, we applied univariate analysis and SVC-L1 regularization to identify features that can effectively differentiate inhibitors from non-inhibitors. Using these selected features, we developed machine learning models, our support vector classifier achieved a highest AUC of 0.75 on the validation dataset.
Discussion: Finally, this best-performing model was employed to screen FDA-approved drugs for potential NF-κB inhibitors. Notably, most of the predicted inhibitors corresponded to drugs previously identified as inhibitors in experimental studies, underscoring the model's predictive reliability. Our best-performing models have been integrated into a standalone software and web server, NfκBin. (https://webs.iiitd.edu.in/raghava/nfkbin/).

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


