Shane A Bobart, Enshuo Hsu, Thomas Potter, Luan Truong, Amy Waterman, Stephen Jones, Tariq Shafi
{"title":"Development of a Natural Language Processing Model for Extracting Kidney Biopsy Pathology Diagnoses.","authors":"Shane A Bobart, Enshuo Hsu, Thomas Potter, Luan Truong, Amy Waterman, Stephen Jones, Tariq Shafi","doi":"10.1016/j.xkme.2025.101047","DOIUrl":null,"url":null,"abstract":"<p><strong>Rationale & objective: </strong>Kidney biopsy reports are in a nonindexed text format, and the diagnosis requires labor-intensive manual abstraction. Natural language processing (NLP) has not been rigorously tested for kidney biopsy diagnosis extraction. Our objective was to develop an accurate model to extract the biopsy diagnosis from free-text reports.</p><p><strong>Study design: </strong>Text classification using NLP.</p><p><strong>Setting & participants: </strong>2,666 patients with 3,042 native kidney biopsy reports in the Portable Document Format, from June 2016 to December 2023.</p><p><strong>Predictor: </strong>Kidney biopsy diagnosis.</p><p><strong>Outcomes: </strong>The performance of the NLP algorithm for all and the 20 most common diagnoses based on precision, recall, F1 score, and area under the receiver operating curve (AUROC).</p><p><strong>Analytical approach: </strong>A domain expert manually abstracted the diagnosis, and a renal pathologist validated a random subset (n = 200). Structured Query Language server and Python processed reports into machine-readable free text. We used PubMed Bidirectional Encoder Representations from Transformers to develop our NLP algorithm. We randomly split the reports into training (80%; n = 2,434) and testing (20%; n = 608) sets to train the NLP system. We further divided the testing set into 20% validation and 80% fine-tuning sets.</p><p><strong>Results: </strong>The median age was 57 years, with 50% female, 29% African Americans, and 23% Hispanic participants. The 5 most frequent glomerular diagnoses were diabetic kidney disease (23.7%), focal segmental glomerulosclerosis (15.5%), lupus nephritis (9.7%), immunoglobulin A nephropathy (8.9), and membranous nephropathy (7.2%). The Cohen kappa coefficient for interrater reliability was 0.76. PubMed Bidirectional Encoder Representations from Transformers fine-tuned with a training set showed the average AUROC for NLP performance in the testing set of 0.95 across all diagnoses with an F1 score of 0.57. For the 20 most common diagnoses, the AUROC was 0.97 with an F1 score of 0.72. Limitations: Single centered; sample size and use limited to research purposes.</p><p><strong>Conclusions: </strong>We demonstrate an accurate and scalable NLP system to extract the primary diagnosis from free-text kidney biopsy reports, which can facilitate epidemiologic studies and identify patients for clinical trial recruitment.</p>","PeriodicalId":17885,"journal":{"name":"Kidney Medicine","volume":"7 8","pages":"101047"},"PeriodicalIF":3.4000,"publicationDate":"2025-06-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12311501/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Kidney Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.xkme.2025.101047","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/8/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"UROLOGY & NEPHROLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Rationale & objective: Kidney biopsy reports are in a nonindexed text format, and the diagnosis requires labor-intensive manual abstraction. Natural language processing (NLP) has not been rigorously tested for kidney biopsy diagnosis extraction. Our objective was to develop an accurate model to extract the biopsy diagnosis from free-text reports.
Study design: Text classification using NLP.
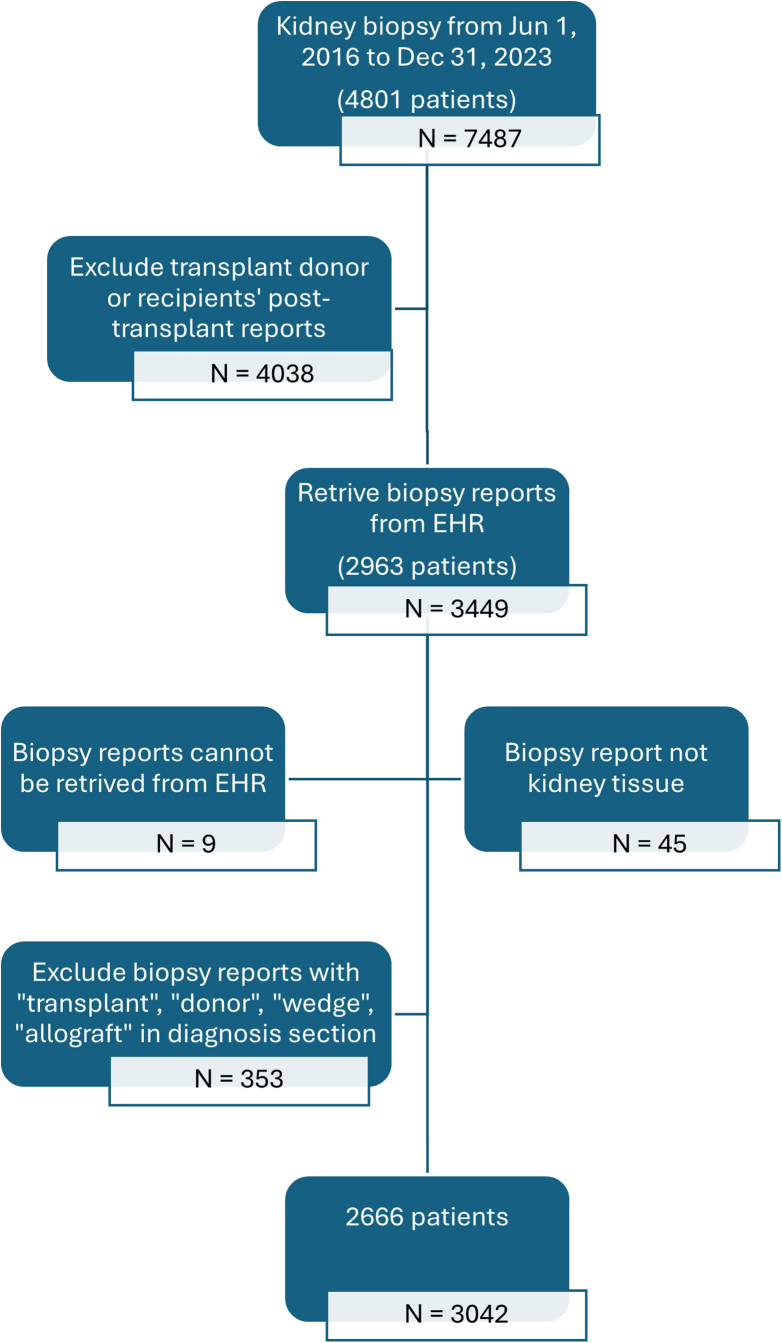
Setting & participants: 2,666 patients with 3,042 native kidney biopsy reports in the Portable Document Format, from June 2016 to December 2023.
Predictor: Kidney biopsy diagnosis.
Outcomes: The performance of the NLP algorithm for all and the 20 most common diagnoses based on precision, recall, F1 score, and area under the receiver operating curve (AUROC).
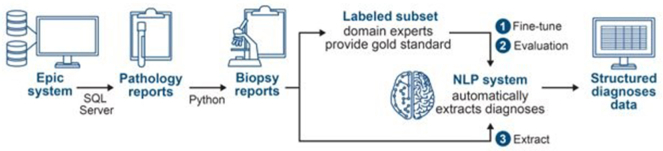
Analytical approach: A domain expert manually abstracted the diagnosis, and a renal pathologist validated a random subset (n = 200). Structured Query Language server and Python processed reports into machine-readable free text. We used PubMed Bidirectional Encoder Representations from Transformers to develop our NLP algorithm. We randomly split the reports into training (80%; n = 2,434) and testing (20%; n = 608) sets to train the NLP system. We further divided the testing set into 20% validation and 80% fine-tuning sets.
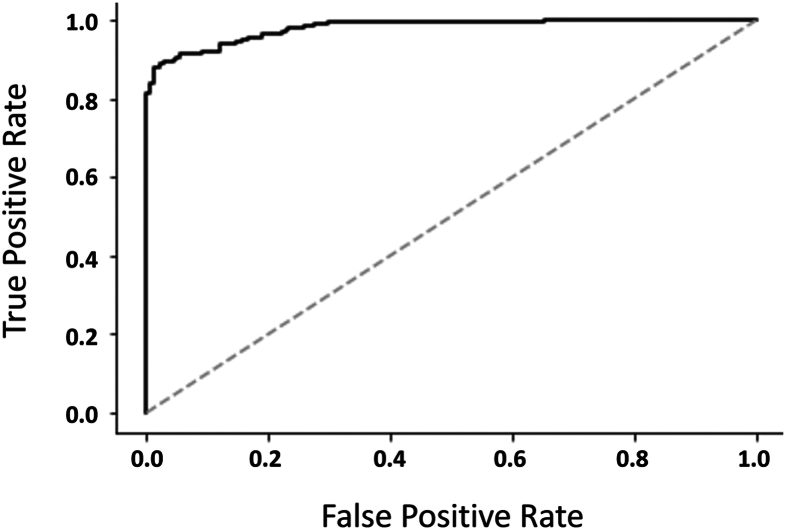
Results: The median age was 57 years, with 50% female, 29% African Americans, and 23% Hispanic participants. The 5 most frequent glomerular diagnoses were diabetic kidney disease (23.7%), focal segmental glomerulosclerosis (15.5%), lupus nephritis (9.7%), immunoglobulin A nephropathy (8.9), and membranous nephropathy (7.2%). The Cohen kappa coefficient for interrater reliability was 0.76. PubMed Bidirectional Encoder Representations from Transformers fine-tuned with a training set showed the average AUROC for NLP performance in the testing set of 0.95 across all diagnoses with an F1 score of 0.57. For the 20 most common diagnoses, the AUROC was 0.97 with an F1 score of 0.72. Limitations: Single centered; sample size and use limited to research purposes.
Conclusions: We demonstrate an accurate and scalable NLP system to extract the primary diagnosis from free-text kidney biopsy reports, which can facilitate epidemiologic studies and identify patients for clinical trial recruitment.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


