GutGPT: A multidimensional knowledge-enhanced large language model for gastrointestinal medicine
IF 4.5
2区 医学
Q2 COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS
引用次数: 0
Abstract
Background
Gastrointestinal (GI) diseases are common, chronic conditions that require personalized, long-term management, placing a heavy burden on traditional healthcare systems. While large language models (LLMs) offer potential for supporting patient care with personalized and empathetic guidance, existing models often lack domain-specific knowledge in GI diseases and suffer from issues like slow convergence and overfitting.
Methodology
We first construct a high-quality GI disease QA dataset comprising 191,615 entries from diverse sources: real-world doctor-patient dialogues, medical knowledge graphs, medical guidelines, and Chinese medical licensing exam data. Then, we introduce GutGPT, an LLM fine-tuned from Baichuan-13B-Chat using Low-Rank Adaptation (LoRA) technology with self-attention mechanism parameter sharing. To evaluate the performance of GutGPT and other existing LLMs, we use a combination of expert evaluation and public dataset testing to comprehensively assess each model’s accuracy and empathy.
Results
We conduct comprehensive evaluations, including expert evaluations and evaluations on multiple benchmark datasets. The results show that our model outperforms 16 existing methods and achieves state-of-the-art performance. In expert evaluations, GutGPT improves diagnostic accuracy by 9.59% compared to the baselines. On two public medical QA datasets, CMB and CMExam, it achieves an average accuracy improvement of 22.47%.
Conclusions
GutGPT achieves high accuracy in managing GI disease patients and demonstrates strong empathy. It serves as an important auxiliary tool for both patients and physicians in disease management.
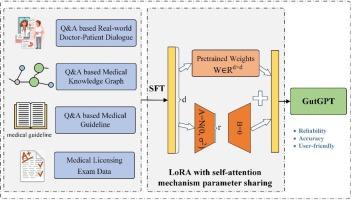
GutGPT:用于胃肠医学的多维知识增强大语言模型
胃肠道疾病是一种常见的慢性疾病,需要个性化的长期管理,给传统卫生保健系统带来了沉重的负担。虽然大型语言模型(llm)提供了通过个性化和移情指导来支持患者护理的潜力,但现有模型通常缺乏胃肠道疾病的领域特定知识,并且存在缓慢收敛和过拟合等问题。我们首先构建了一个高质量的胃肠道疾病QA数据集,包括来自不同来源的191,615个条目:现实世界的医患对话、医学知识图谱、医疗指南和中国医师执照考试数据。然后,我们引入了一种基于低阶自适应(Low-Rank Adaptation, LoRA)技术、自关注机制参数共享的从百川- 13b - chat中微调的LLM——GutGPT。为了评估GutGPT和其他现有llm的性能,我们使用专家评估和公共数据集测试相结合的方法来综合评估每个模型的准确性和同理心。结果我们进行了综合评估,包括专家评估和对多个基准数据集的评估。结果表明,我们的模型优于现有的16种方法,达到了最先进的性能。在专家评估中,与基线相比,GutGPT的诊断准确率提高了9.59%。在CMB和CMExam两个公共医疗QA数据集上,平均准确率提高了22.47%。结论gutgpt对胃肠道疾病患者的管理具有较高的准确性和较强的共情能力。它是一种重要的辅助工具,为病人和医生在疾病管理。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Journal of Biomedical Informatics
医学-计算机:跨学科应用
CiteScore
8.90
自引率
6.70%
发文量
243
审稿时长
32 days
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


