Ben Bloom, Adrian Haimovich, Jason Pott, Sophie L Williams, Michael Cheetham, Sandra Langsted, Imogen Skene, Raine Astin-Chamberlain, Stephen H Thomas
{"title":"Digitalizing English-language CT Interpretation for Positive Haemorrhage Evaluation Reporting: the DECIPHER study.","authors":"Ben Bloom, Adrian Haimovich, Jason Pott, Sophie L Williams, Michael Cheetham, Sandra Langsted, Imogen Skene, Raine Astin-Chamberlain, Stephen H Thomas","doi":"10.1136/bmjhci-2025-101433","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Identifying whether there is a traumatic intracranial bleed (ICB+) on head CT is critical for clinical care and research. Free text CT reports are unstructured and therefore must undergo time-consuming manual review. Existing artificial intelligence classification schemes are not optimised for the emergency department endpoint of classification of ICB+ or ICB-. We sought to assess three methods for classifying CT reports: a text classification (TC) programme, a commercial natural language processing programme (Clinithink) and a generative pretrained transformer large language model (Digitalizing English-language CT Interpretation for Positive Haemorrhage Evaluation Reporting (DECIPHER)-LLM).</p><p><strong>Methods: </strong>Primary objective: determine the diagnostic classification performance of the dichotomous categorisation of each of the three approaches.</p><p><strong>Secondary objective: </strong>determine whether the LLM could achieve a substantial reduction in CT report review workload while maintaining 100% sensitivity.Anonymised radiology reports of head CT scans performed for trauma were manually labelled as ICB+/-. Training and validation sets were randomly created to train the TC and natural language processing models. Prompts were written to train the LLM.</p><p><strong>Results: </strong>898 reports were manually labelled. Sensitivity and specificity (95% CI)) of TC, Clinithink and DECIPHER-LLM (with probability of ICB set at 10%) were respectively 87.9% (76.7% to 95.0%) and 98.2% (96.3% to 99.3%), 75.9% (62.8% to 86.1%) and 96.2% (93.8% to 97.8%) and 100% (93.8% to 100%) and 97.4% (95.3% to 98.8%).With DECIPHER-LLM probability of ICB+ threshold of 10% set to identify CT reports requiring manual evaluation, CT reports requiring manual classification reduced by an estimated 385/449 cases (85.7% (95% CI 82.1% to 88.9%)) while maintaining 100% sensitivity.</p><p><strong>Discussion and conclusion: </strong>DECIPHER-LLM outperformed other tested free-text classification methods.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"32 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2025-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12306305/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2025-101433","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: Identifying whether there is a traumatic intracranial bleed (ICB+) on head CT is critical for clinical care and research. Free text CT reports are unstructured and therefore must undergo time-consuming manual review. Existing artificial intelligence classification schemes are not optimised for the emergency department endpoint of classification of ICB+ or ICB-. We sought to assess three methods for classifying CT reports: a text classification (TC) programme, a commercial natural language processing programme (Clinithink) and a generative pretrained transformer large language model (Digitalizing English-language CT Interpretation for Positive Haemorrhage Evaluation Reporting (DECIPHER)-LLM).
Methods: Primary objective: determine the diagnostic classification performance of the dichotomous categorisation of each of the three approaches.
Secondary objective: determine whether the LLM could achieve a substantial reduction in CT report review workload while maintaining 100% sensitivity.Anonymised radiology reports of head CT scans performed for trauma were manually labelled as ICB+/-. Training and validation sets were randomly created to train the TC and natural language processing models. Prompts were written to train the LLM.
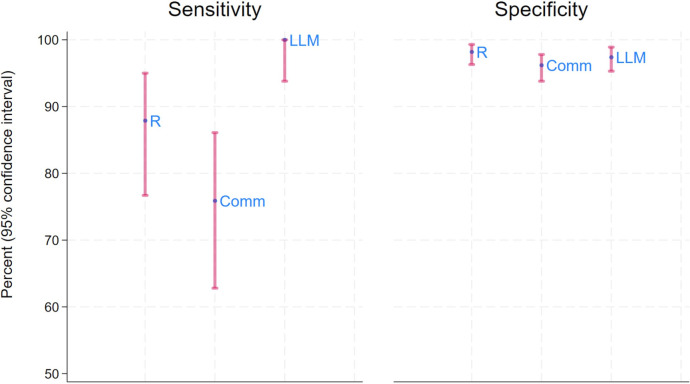
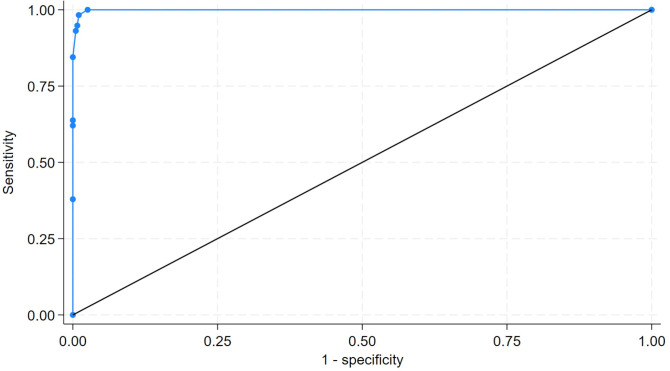
Results: 898 reports were manually labelled. Sensitivity and specificity (95% CI)) of TC, Clinithink and DECIPHER-LLM (with probability of ICB set at 10%) were respectively 87.9% (76.7% to 95.0%) and 98.2% (96.3% to 99.3%), 75.9% (62.8% to 86.1%) and 96.2% (93.8% to 97.8%) and 100% (93.8% to 100%) and 97.4% (95.3% to 98.8%).With DECIPHER-LLM probability of ICB+ threshold of 10% set to identify CT reports requiring manual evaluation, CT reports requiring manual classification reduced by an estimated 385/449 cases (85.7% (95% CI 82.1% to 88.9%)) while maintaining 100% sensitivity.
Discussion and conclusion: DECIPHER-LLM outperformed other tested free-text classification methods.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


