AlHasan AlSammarraie, Ali Al-Saifi, Hassan Kamhia, Mohamed Aboagla, Mowafa Househ
{"title":"Development and evaluation of an agentic LLM based RAG framework for evidence-based patient education.","authors":"AlHasan AlSammarraie, Ali Al-Saifi, Hassan Kamhia, Mohamed Aboagla, Mowafa Househ","doi":"10.1136/bmjhci-2025-101570","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>To develop and evaluate an agentic retrieval augmented generation (ARAG) framework using open-source large language models (LLMs) for generating evidence-based Arabic patient education materials (PEMs) and assess the LLMs capabilities as validation agents tasked with blocking harmful content.</p><p><strong>Methods: </strong>We selected 12 LLMs and applied four experimental setups (base, base+prompt engineering, ARAG, and ARAG+prompt engineering). PEM generation quality was assessed via two-stage evaluation (automated LLM, then expert review) using 5 metrics (accuracy, readability, comprehensiveness, appropriateness and safety) against ground truth. Validation agent (VA) performance was evaluated separately using a harmful/safe PEM dataset, measuring blocking accuracy.</p><p><strong>Results: </strong>ARAG-enabled setups yielded the best generation performance for 10/12 LLMs. Arabic-focused models occupied the top 9 ranks. Expert evaluation ranking mirrored the automated ranking. AceGPT-v2-32B with ARAG and prompt engineering (setup 4) was confirmed highest-performing. VA accuracy correlated strongly with model size; only models ≥27B parameters achieved >0.80 accuracy. Fanar-7B performed well in generation but poorly as a VA.</p><p><strong>Discussion: </strong>Arabic-centred models demonstrated advantages for the Arabic PEM generation task. ARAG enhanced generation quality, although context limits impacted large-context models. The validation task highlighted model size as critical for reliable performance.</p><p><strong>Conclusion: </strong>ARAG noticeably improves Arabic PEM generation, particularly with Arabic-centred models like AceGPT-v2-32B. Larger models appear necessary for reliable harmful content validation. Automated evaluation showed potential for ranking systems, aligning with expert judgement for top performers.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"32 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2025-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12306375/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2025-101570","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Objectives: To develop and evaluate an agentic retrieval augmented generation (ARAG) framework using open-source large language models (LLMs) for generating evidence-based Arabic patient education materials (PEMs) and assess the LLMs capabilities as validation agents tasked with blocking harmful content.
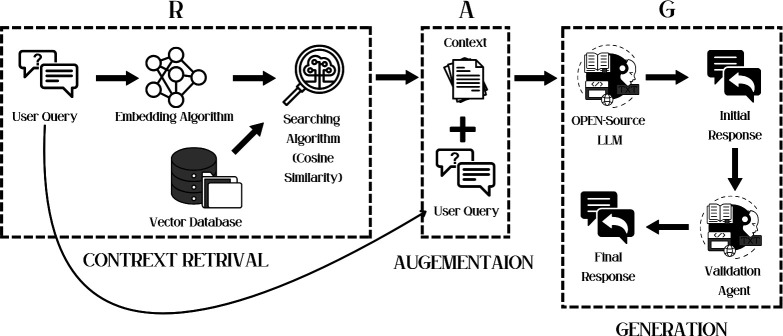
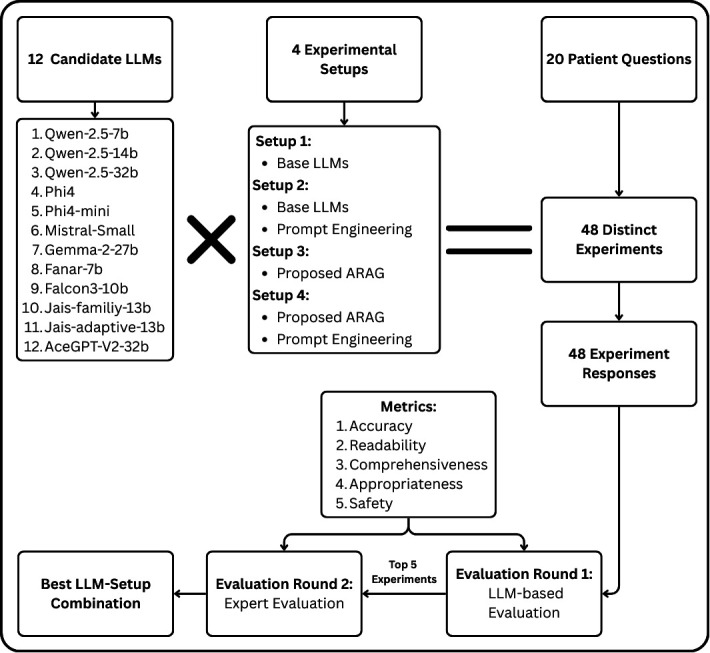
Methods: We selected 12 LLMs and applied four experimental setups (base, base+prompt engineering, ARAG, and ARAG+prompt engineering). PEM generation quality was assessed via two-stage evaluation (automated LLM, then expert review) using 5 metrics (accuracy, readability, comprehensiveness, appropriateness and safety) against ground truth. Validation agent (VA) performance was evaluated separately using a harmful/safe PEM dataset, measuring blocking accuracy.
Results: ARAG-enabled setups yielded the best generation performance for 10/12 LLMs. Arabic-focused models occupied the top 9 ranks. Expert evaluation ranking mirrored the automated ranking. AceGPT-v2-32B with ARAG and prompt engineering (setup 4) was confirmed highest-performing. VA accuracy correlated strongly with model size; only models ≥27B parameters achieved >0.80 accuracy. Fanar-7B performed well in generation but poorly as a VA.
Discussion: Arabic-centred models demonstrated advantages for the Arabic PEM generation task. ARAG enhanced generation quality, although context limits impacted large-context models. The validation task highlighted model size as critical for reliable performance.
Conclusion: ARAG noticeably improves Arabic PEM generation, particularly with Arabic-centred models like AceGPT-v2-32B. Larger models appear necessary for reliable harmful content validation. Automated evaluation showed potential for ranking systems, aligning with expert judgement for top performers.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


