Lulu Li, Pengqiang Du, Xiaojing Huang, Hongwei Zhao, Ming Ni, Meng Yan, Aifeng Wang
{"title":"Comparative Analysis of Generative Artificial Intelligence Systems in Solving Clinical Pharmacy Problems: Mixed Methods Study.","authors":"Lulu Li, Pengqiang Du, Xiaojing Huang, Hongwei Zhao, Ming Ni, Meng Yan, Aifeng Wang","doi":"10.2196/76128","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Generative artificial intelligence (AI) systems are increasingly deployed in clinical pharmacy; yet, systematic evaluation of their efficacy, limitations, and risks across diverse practice scenarios remains limited.</p><p><strong>Objective: </strong>This study aims to quantitatively evaluate and compare the performance of 8 mainstream generative AI systems across 4 core clinical pharmacy scenarios-medication consultation, medication education, prescription review, and case analysis with pharmaceutical care-using a multidimensional framework.</p><p><strong>Methods: </strong>Forty-eight clinically validated questions were selected via stratified sampling from real-world sources (eg, hospital consultations, clinical case banks, and national pharmacist training databases). Three researchers simultaneously tested 8 different generative AI systems (ERNIE Bot, Doubao, Kimi, Qwen, GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet, and DeepSeek-R1) using standardized prompts within a single day (February 20, 2025). A double-blind scoring design was used, with 6 experienced clinical pharmacists (≥5 years experience) evaluating the AI responses across 6 dimensions: accuracy, rigor, applicability, logical coherence, conciseness, and universality, scored 0-10 per predefined criteria (eg, -3 for inaccuracy and -2 for incomplete rigor). Statistical analysis used one-way ANOVA with Tukey Honestly Significant Difference (HSD) post hoc testing and intraclass correlation coefficients (ICC) for interrater reliability (2-way random model). Qualitative thematic analysis identified recurrent errors and limitations.</p><p><strong>Results: </strong>DeepSeek-R1 (DeepSeek) achieved the highest overall performance (mean composite score: medication consultation 9.4, SD 1.0; case analysis 9.3, SD 1.0), significantly outperforming others in complex tasks (P<.05). Critical limitations were observed across models, including high-risk decision errors-75% omitted critical contraindications (eg, ethambutol in optic neuritis) and a lack of localization-90% erroneously recommended macrolides for drug-resistant Mycoplasma pneumoniae (China's high-resistance setting), while only DeepSeek-R1 aligned with updated American Academy of Pediatrics (AAP) guidelines for pediatric doxycycline. Complex reasoning deficits: only Claude-3.5-Sonnet detected a gender-diagnosis contradiction (prostatic hyperplasia in female); no model identified diazepam's 7-day prescription limit. Interrater consistency was lowest for conciseness in case analysis (ICC=0.70), reflecting evaluator disagreement on complex outputs. ERNIE Bot (Baidu) consistently underperformed (case analysis: 6.8, SD 1.5; P<.001 vs DeepSeek-R1).</p><p><strong>Conclusions: </strong>While generative AI shows promise as a pharmacist assistance tool, significant limitations-including high-risk errors (eg, contraindication omissions), inadequate localization, and complex reasoning gaps-preclude autonomous clinical decision-making. Performance stratification highlights DeepSeek-R1's current advantage, but all systems require optimization in dynamic knowledge updating, complex scenario reasoning, and output interpretability. Future deployment must prioritize human oversight (human-AI co-review), ethical safeguards, and continuous evaluation frameworks.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e76128"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12288765/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/76128","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Generative artificial intelligence (AI) systems are increasingly deployed in clinical pharmacy; yet, systematic evaluation of their efficacy, limitations, and risks across diverse practice scenarios remains limited.
Objective: This study aims to quantitatively evaluate and compare the performance of 8 mainstream generative AI systems across 4 core clinical pharmacy scenarios-medication consultation, medication education, prescription review, and case analysis with pharmaceutical care-using a multidimensional framework.
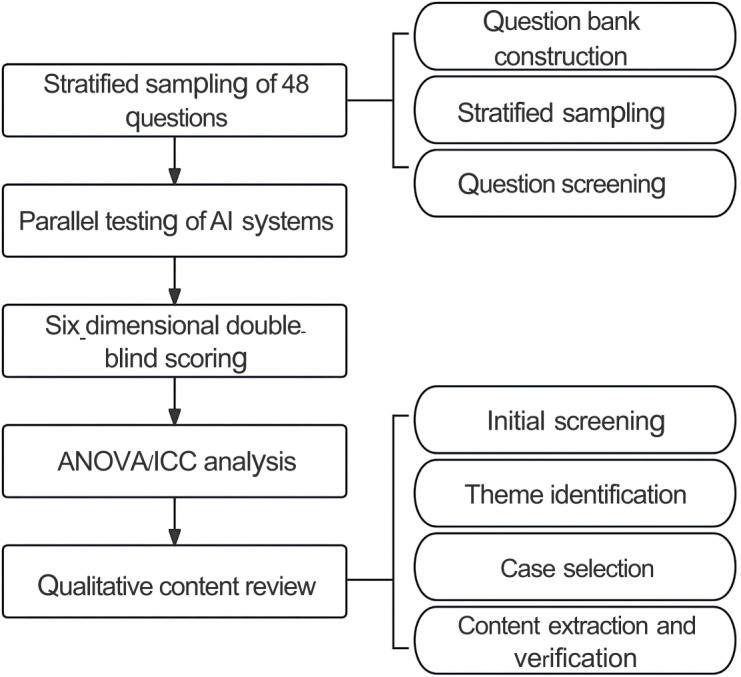
Methods: Forty-eight clinically validated questions were selected via stratified sampling from real-world sources (eg, hospital consultations, clinical case banks, and national pharmacist training databases). Three researchers simultaneously tested 8 different generative AI systems (ERNIE Bot, Doubao, Kimi, Qwen, GPT-4o, Gemini-1.5-Pro, Claude-3.5-Sonnet, and DeepSeek-R1) using standardized prompts within a single day (February 20, 2025). A double-blind scoring design was used, with 6 experienced clinical pharmacists (≥5 years experience) evaluating the AI responses across 6 dimensions: accuracy, rigor, applicability, logical coherence, conciseness, and universality, scored 0-10 per predefined criteria (eg, -3 for inaccuracy and -2 for incomplete rigor). Statistical analysis used one-way ANOVA with Tukey Honestly Significant Difference (HSD) post hoc testing and intraclass correlation coefficients (ICC) for interrater reliability (2-way random model). Qualitative thematic analysis identified recurrent errors and limitations.
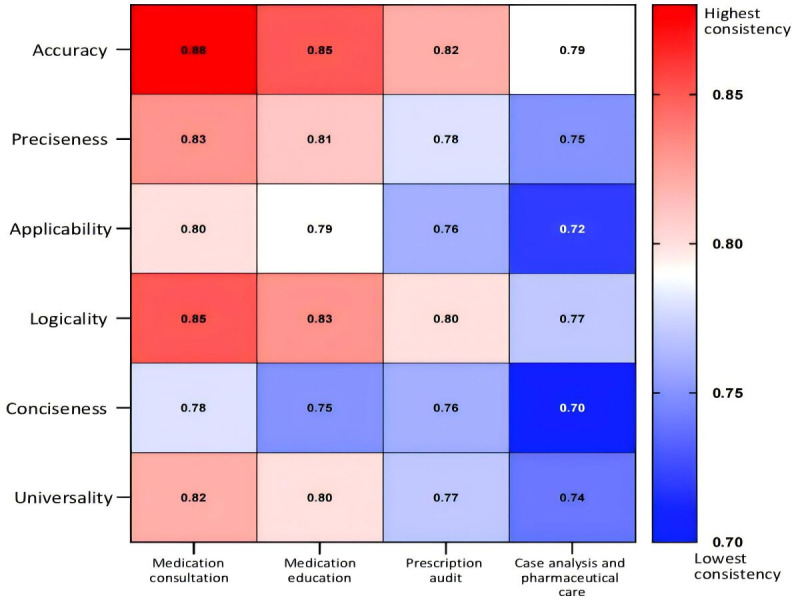
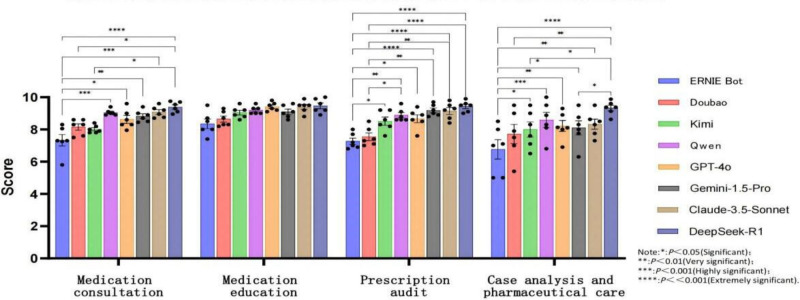
Results: DeepSeek-R1 (DeepSeek) achieved the highest overall performance (mean composite score: medication consultation 9.4, SD 1.0; case analysis 9.3, SD 1.0), significantly outperforming others in complex tasks (P<.05). Critical limitations were observed across models, including high-risk decision errors-75% omitted critical contraindications (eg, ethambutol in optic neuritis) and a lack of localization-90% erroneously recommended macrolides for drug-resistant Mycoplasma pneumoniae (China's high-resistance setting), while only DeepSeek-R1 aligned with updated American Academy of Pediatrics (AAP) guidelines for pediatric doxycycline. Complex reasoning deficits: only Claude-3.5-Sonnet detected a gender-diagnosis contradiction (prostatic hyperplasia in female); no model identified diazepam's 7-day prescription limit. Interrater consistency was lowest for conciseness in case analysis (ICC=0.70), reflecting evaluator disagreement on complex outputs. ERNIE Bot (Baidu) consistently underperformed (case analysis: 6.8, SD 1.5; P<.001 vs DeepSeek-R1).
Conclusions: While generative AI shows promise as a pharmacist assistance tool, significant limitations-including high-risk errors (eg, contraindication omissions), inadequate localization, and complex reasoning gaps-preclude autonomous clinical decision-making. Performance stratification highlights DeepSeek-R1's current advantage, but all systems require optimization in dynamic knowledge updating, complex scenario reasoning, and output interpretability. Future deployment must prioritize human oversight (human-AI co-review), ethical safeguards, and continuous evaluation frameworks.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


