Deyi Li, Aditi Shukla, Sravani Chandaka, Bradley Taylor, Jie Xu, Mei Liu
{"title":"Autoencoder-Based Representation Learning for Similar Patients Retrieval From Electronic Health Records: Comparative Study.","authors":"Deyi Li, Aditi Shukla, Sravani Chandaka, Bradley Taylor, Jie Xu, Mei Liu","doi":"10.2196/68830","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>By analyzing electronic health record snapshots of similar patients, physicians can proactively predict disease onsets, customize treatment plans, and anticipate patient-specific trajectories. However, the modeling of electronic health record data is inherently challenging due to its high dimensionality, mixed feature types, noise, bias, and sparsity. Patient representation learning using autoencoders (AEs) presents promising opportunities to address these challenges. A critical question remains: how do different AE designs and distance measures impact the quality of retrieved similar patient cohorts?</p><p><strong>Objective: </strong>This study aims to evaluate the performance of 5 common AE variants-vanilla autoencoder, denoising autoencoder, contractive autoencoder, sparse autoencoder, and robust autoencoder-in retrieving similar patients. Additionally, it investigates the impact of different distance measures and hyperparameter configurations on model performance.</p><p><strong>Methods: </strong>We tested the 5 AE variants on 2 real-world datasets-the University of Kansas Medical Center (n=13,752) and the Medical College of Wisconsin (n=9568)-across 168 different hyperparameter configurations. To retrieve similar patients based on the AE-produced latent representations, we applied k-nearest neighbors (k-NN) using Euclidean and Mahalanobis distances. Two prediction targets were evaluated: acute kidney injury onset and postdischarge 1-year mortality.</p><p><strong>Results: </strong>Our findings demonstrate that (1) denoising autoencoders outperformed other AE variants when paired with Euclidean distance (P<.001), followed by vanilla autoencoders and contractive autoencoders; (2) learning rates significantly influenced the performance of AE variants; and (3) Mahalanobis distance-based k-NN frequently outperformed Euclidean distance-based k-NN when applied to latent representations. However, whether AE models are superior in transforming raw data into latent representations, compared with applying Mahalanobis distance-based k-NN directly to raw data, appears to be data-dependent.</p><p><strong>Conclusions: </strong>This study provides a comprehensive analysis of the performance of different AE variants in retrieving similar patients and evaluates the impact of various hyperparameter configurations on model performance. The findings lay the groundwork for future development of AE-based patient similarity estimation and personalized medicine.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e68830"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12289314/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/68830","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: By analyzing electronic health record snapshots of similar patients, physicians can proactively predict disease onsets, customize treatment plans, and anticipate patient-specific trajectories. However, the modeling of electronic health record data is inherently challenging due to its high dimensionality, mixed feature types, noise, bias, and sparsity. Patient representation learning using autoencoders (AEs) presents promising opportunities to address these challenges. A critical question remains: how do different AE designs and distance measures impact the quality of retrieved similar patient cohorts?
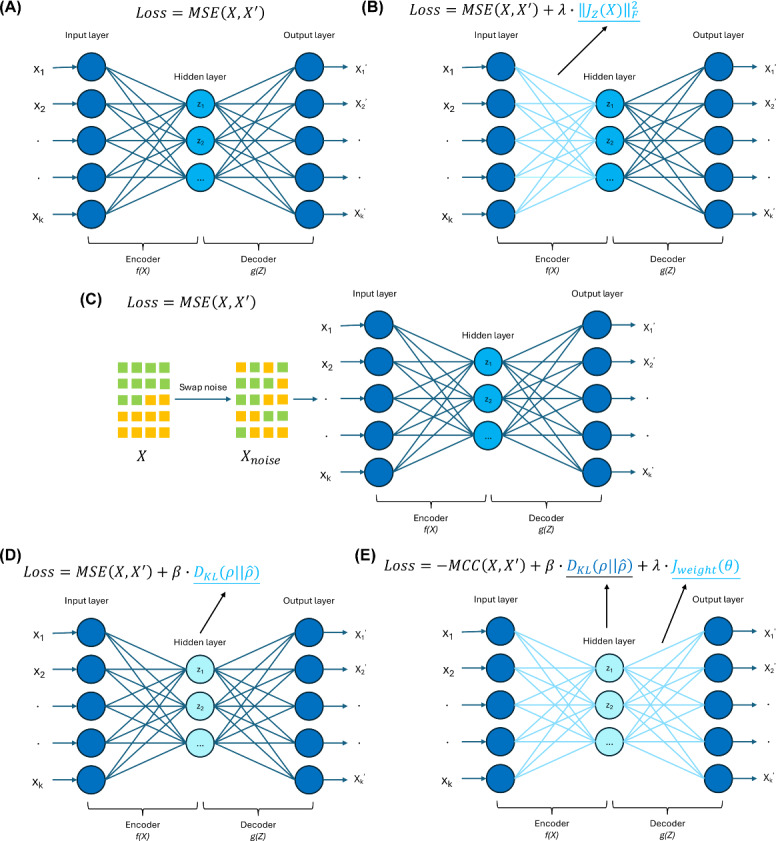
Objective: This study aims to evaluate the performance of 5 common AE variants-vanilla autoencoder, denoising autoencoder, contractive autoencoder, sparse autoencoder, and robust autoencoder-in retrieving similar patients. Additionally, it investigates the impact of different distance measures and hyperparameter configurations on model performance.
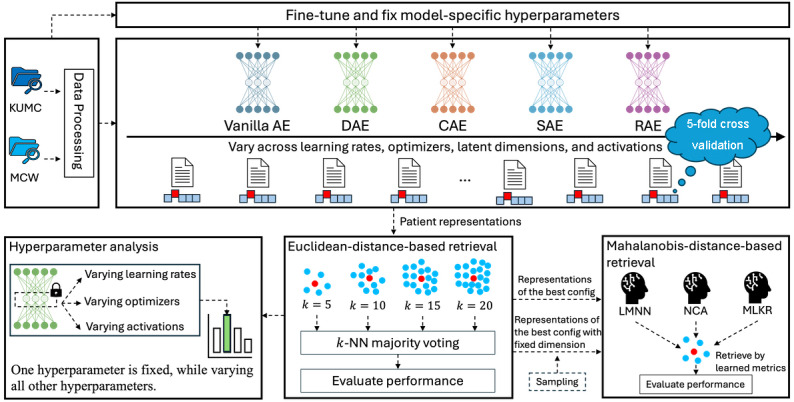
Methods: We tested the 5 AE variants on 2 real-world datasets-the University of Kansas Medical Center (n=13,752) and the Medical College of Wisconsin (n=9568)-across 168 different hyperparameter configurations. To retrieve similar patients based on the AE-produced latent representations, we applied k-nearest neighbors (k-NN) using Euclidean and Mahalanobis distances. Two prediction targets were evaluated: acute kidney injury onset and postdischarge 1-year mortality.
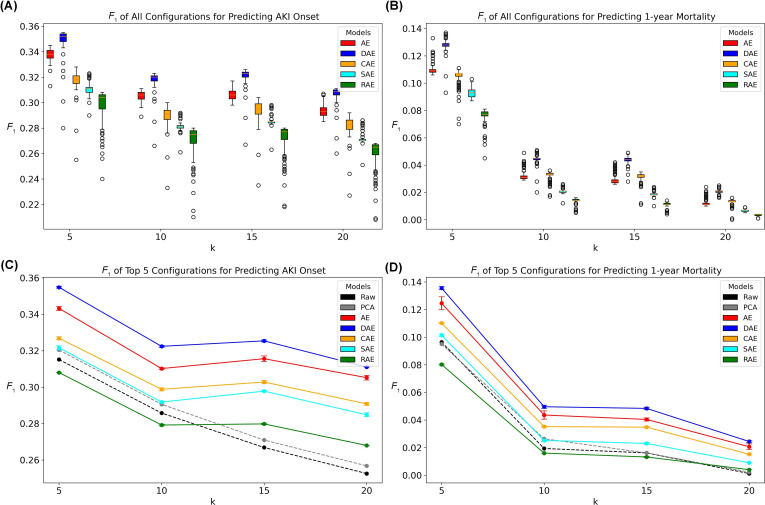
Results: Our findings demonstrate that (1) denoising autoencoders outperformed other AE variants when paired with Euclidean distance (P<.001), followed by vanilla autoencoders and contractive autoencoders; (2) learning rates significantly influenced the performance of AE variants; and (3) Mahalanobis distance-based k-NN frequently outperformed Euclidean distance-based k-NN when applied to latent representations. However, whether AE models are superior in transforming raw data into latent representations, compared with applying Mahalanobis distance-based k-NN directly to raw data, appears to be data-dependent.
Conclusions: This study provides a comprehensive analysis of the performance of different AE variants in retrieving similar patients and evaluates the impact of various hyperparameter configurations on model performance. The findings lay the groundwork for future development of AE-based patient similarity estimation and personalized medicine.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


