Mahshad Koohi Habibi Dehkordi, Yehoshua Perl, Fadi P Deek, Zhe He, Vipina K Keloth, Hao Liu, Gai Elhanan, Andrew J Einstein
{"title":"Improving Large Language Models' Summarization Accuracy by Adding Highlights to Discharge Notes: Comparative Evaluation.","authors":"Mahshad Koohi Habibi Dehkordi, Yehoshua Perl, Fadi P Deek, Zhe He, Vipina K Keloth, Hao Liu, Gai Elhanan, Andrew J Einstein","doi":"10.2196/66476","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The American Medical Association recommends that electronic health record (EHR) notes, often dense and written in nuanced language, be made readable for patients and laypeople, a practice we refer to as the simplification of discharge notes. Our approach to achieving the simplification of discharge notes involves a process of incremental simplification steps to achieve the ideal note. In this paper, we present the first step of this process. Large language models (LLMs) have demonstrated considerable success in text summarization. Such LLM summaries represent the content of EHR notes in an easier-to-read language. However, LLM summaries can also introduce inaccuracies.</p><p><strong>Objective: </strong>This study aims to test the hypothesis that summaries generated by LLMs from highlighted discharge notes will achieve increased accuracy compared to those generated from the original notes. For this purpose, we aim to prove a hypothesis that summaries generated by LLMs of discharge notes in which detailed information is highlighted are likely to be more accurate than summaries of the original notes.</p><p><strong>Methods: </strong>To test our hypothesis, we randomly sampled 15 discharge notes from the MIMIC III database and highlighted their detailed information using an interface terminology we previously developed with machine learning. This interface terminology was curated to encompass detailed information from the discharge notes. The highlighted discharge notes distinguished detailed information, specifically the concepts present in the aforementioned interface terminology, by applying a blue background. To calibrate the LLMs' summaries for our simplification goal, we chose GPT-4o and used prompt engineering to ensure high-quality prompts and address issues of output inconsistency and prompt sensitivity. We provided both highlighted and unhighlighted versions of each EHR note along with their corresponding prompts to GPT-4o. Each generated summary was manually evaluated to assess its quality using the following evaluation metrics: completeness, correctness, and structural integrity.</p><p><strong>Results: </strong>We used the study sample of 15 discharge notes. On average, summaries from highlighted notes (H-summaries) achieved 96% completeness, 8% higher than the summaries from unhighlighted notes (U-summaries). H-summaries had higher completeness in 13 notes, and U-summaries had higher or equal completeness in 2 notes, resulting in P=.01, which implied statistical significance. Moreover, H-summaries demonstrated better correctness than U-summaries, with fewer instances of erroneous information (2 vs 3 errors, respectively). The number of improper headers was smaller for H-summaries for 11 notes and U-summaries for 4 notes (P=.03; implying statistical significance). Moreover, we identified 8 instances of misplaced information in the U-summaries and only 2 in the H-summaries. We showed that our findings supported the hypothesis that summarizing highlighted discharge notes improves the accuracy of the summaries.</p><p><strong>Conclusions: </strong>Feeding LLMs with highlighted discharge notes, combined with prompt engineering, results in higher-quality summaries in terms of correctness, completeness, and structural integrity compared to unhighlighted discharge notes.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e66476"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12332456/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/66476","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The American Medical Association recommends that electronic health record (EHR) notes, often dense and written in nuanced language, be made readable for patients and laypeople, a practice we refer to as the simplification of discharge notes. Our approach to achieving the simplification of discharge notes involves a process of incremental simplification steps to achieve the ideal note. In this paper, we present the first step of this process. Large language models (LLMs) have demonstrated considerable success in text summarization. Such LLM summaries represent the content of EHR notes in an easier-to-read language. However, LLM summaries can also introduce inaccuracies.
Objective: This study aims to test the hypothesis that summaries generated by LLMs from highlighted discharge notes will achieve increased accuracy compared to those generated from the original notes. For this purpose, we aim to prove a hypothesis that summaries generated by LLMs of discharge notes in which detailed information is highlighted are likely to be more accurate than summaries of the original notes.
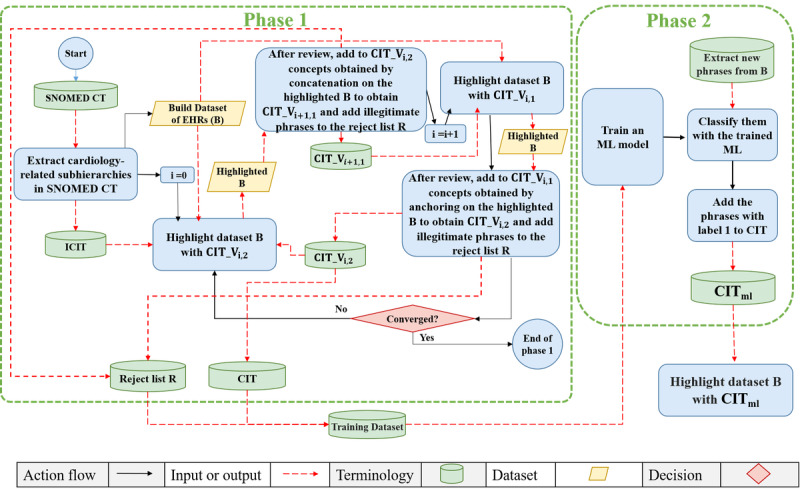
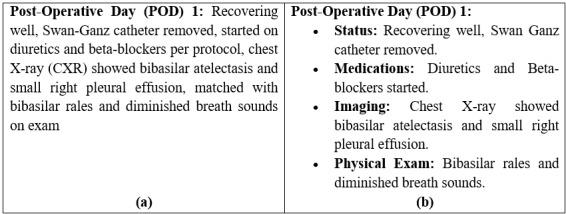
Methods: To test our hypothesis, we randomly sampled 15 discharge notes from the MIMIC III database and highlighted their detailed information using an interface terminology we previously developed with machine learning. This interface terminology was curated to encompass detailed information from the discharge notes. The highlighted discharge notes distinguished detailed information, specifically the concepts present in the aforementioned interface terminology, by applying a blue background. To calibrate the LLMs' summaries for our simplification goal, we chose GPT-4o and used prompt engineering to ensure high-quality prompts and address issues of output inconsistency and prompt sensitivity. We provided both highlighted and unhighlighted versions of each EHR note along with their corresponding prompts to GPT-4o. Each generated summary was manually evaluated to assess its quality using the following evaluation metrics: completeness, correctness, and structural integrity.
Results: We used the study sample of 15 discharge notes. On average, summaries from highlighted notes (H-summaries) achieved 96% completeness, 8% higher than the summaries from unhighlighted notes (U-summaries). H-summaries had higher completeness in 13 notes, and U-summaries had higher or equal completeness in 2 notes, resulting in P=.01, which implied statistical significance. Moreover, H-summaries demonstrated better correctness than U-summaries, with fewer instances of erroneous information (2 vs 3 errors, respectively). The number of improper headers was smaller for H-summaries for 11 notes and U-summaries for 4 notes (P=.03; implying statistical significance). Moreover, we identified 8 instances of misplaced information in the U-summaries and only 2 in the H-summaries. We showed that our findings supported the hypothesis that summarizing highlighted discharge notes improves the accuracy of the summaries.
Conclusions: Feeding LLMs with highlighted discharge notes, combined with prompt engineering, results in higher-quality summaries in terms of correctness, completeness, and structural integrity compared to unhighlighted discharge notes.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


