Wilson Lukmanjaya, Tony Butler, Sarah Cox, Oscar Perez-Concha, Leah Bromfield, George Karystianis
{"title":"Leveraging AI to Investigate Child Maltreatment Text Narratives: Promising Benefits and Addressable Risks.","authors":"Wilson Lukmanjaya, Tony Butler, Sarah Cox, Oscar Perez-Concha, Leah Bromfield, George Karystianis","doi":"10.2196/73579","DOIUrl":null,"url":null,"abstract":"<p><strong>Unlabelled: </strong>The trove of information contained in child maltreatment narratives represents an opportunity to strengthen the evidence base for policy reform in this area, yet it remains underutilized by researchers and policy makers. Current research into child maltreatment often involves the use of qualitative methodologies or structured survey data that are either too broad or not representative, thereby limiting the development of effective policy responses and intervention strategies. Artificial intelligence (AI) approaches such as large language models (AI models that understand and generate language) can analyze large volumes of child maltreatment narratives by extracting population-level insights on factors of interest such as mental health and treatment needs. However, when applying such methods, it is useful to have a framework on which to base approaches to the data. We propose a seven step framework: (1) data governance; (2) researcher vetting; (3) data deidentification; (4) data access; (5) feasibility testing of baseline methods; (6) large-scale implementation of black box algorithms; and (7) domain expert result validation for such exercises to ensure careful execution and limit the risk of privacy and security breaches, bias, and unreliable conclusions.</p>","PeriodicalId":36223,"journal":{"name":"JMIR Pediatrics and Parenting","volume":"8 ","pages":"e73579"},"PeriodicalIF":2.3000,"publicationDate":"2025-07-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12288702/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Pediatrics and Parenting","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/73579","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PEDIATRICS","Score":null,"Total":0}
引用次数: 0
Abstract
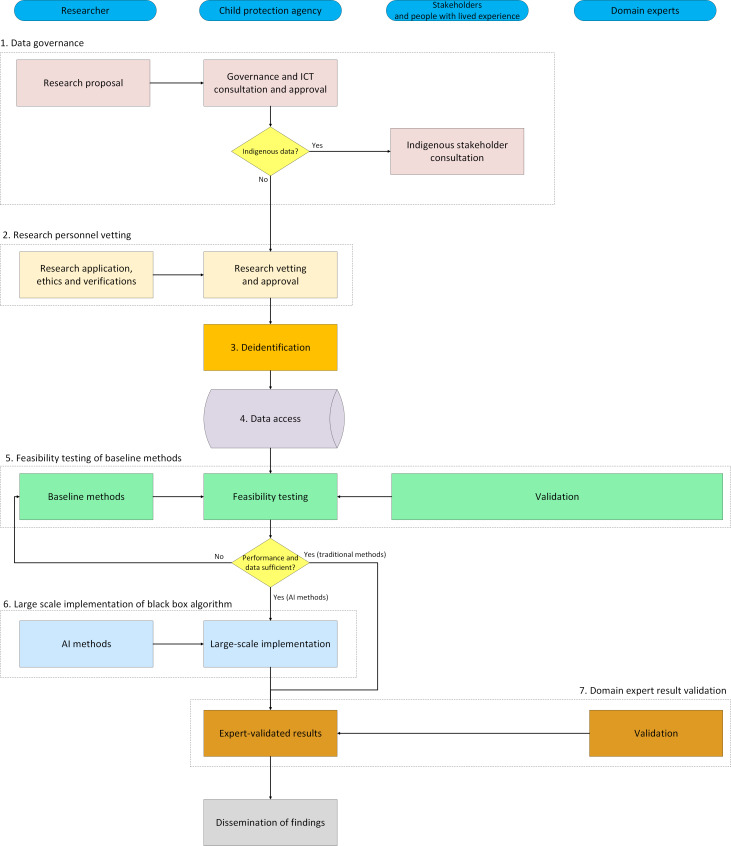
Unlabelled: The trove of information contained in child maltreatment narratives represents an opportunity to strengthen the evidence base for policy reform in this area, yet it remains underutilized by researchers and policy makers. Current research into child maltreatment often involves the use of qualitative methodologies or structured survey data that are either too broad or not representative, thereby limiting the development of effective policy responses and intervention strategies. Artificial intelligence (AI) approaches such as large language models (AI models that understand and generate language) can analyze large volumes of child maltreatment narratives by extracting population-level insights on factors of interest such as mental health and treatment needs. However, when applying such methods, it is useful to have a framework on which to base approaches to the data. We propose a seven step framework: (1) data governance; (2) researcher vetting; (3) data deidentification; (4) data access; (5) feasibility testing of baseline methods; (6) large-scale implementation of black box algorithms; and (7) domain expert result validation for such exercises to ensure careful execution and limit the risk of privacy and security breaches, bias, and unreliable conclusions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


