{"title":"Ensemble learning methods and heterogeneous graph network fusion: building drug-gene-disease triple association prediction models.","authors":"Keichin N G","doi":"10.1093/bib/bbaf369","DOIUrl":null,"url":null,"abstract":"<p><p>The potential association data between drugs, genes, and diseases is sparse and complex. Existing models find it difficult to effectively handle the problem of heterogeneous relationships and multi-source data fusion simultaneously, resulting in limited accuracy and generalization of association prediction. To address this problem, we propose a fusion method of relational graph convolutional network (R-GCN) and eXtreme Gradient Boosting (XGBoost). First, a heterogeneous graph containing drug, gene, and disease nodes and their relationships is constructed. The features of different types of nodes are aggregated and represented by R-GCN to generate high-quality node embeddings. Then, the embedded features of the drug-gene-disease triples are input into the XGBoost model for training to achieve the association prediction task. The findings demonstrate that the model's area under the curve reaches 0.92, and the F1 score reaches 0.85, indicating strong predictive ability. This method solves the problem of association prediction in complex biological networks and brings new technological support for precision medicine.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"26 4","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2025-07-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12286780/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbaf369","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
引用次数: 0
Abstract
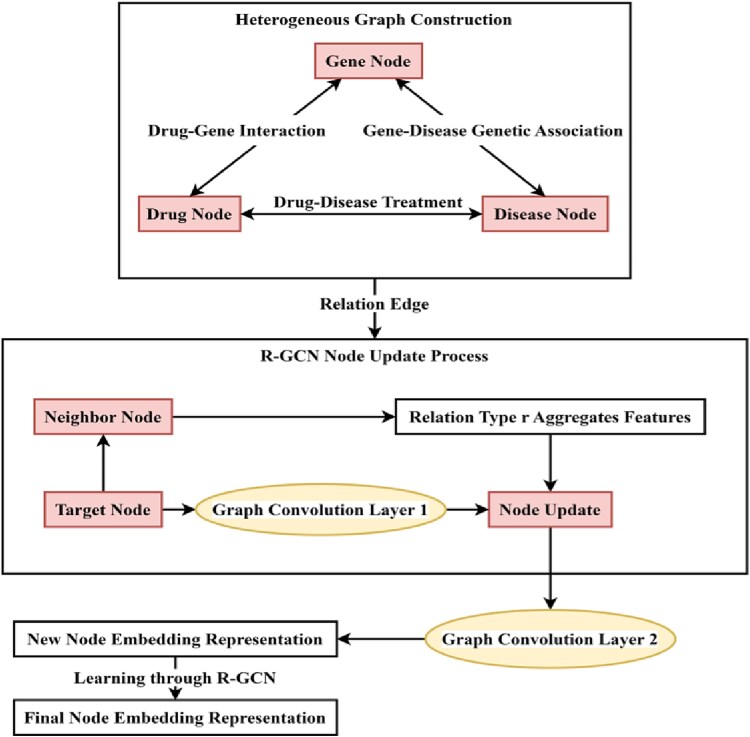
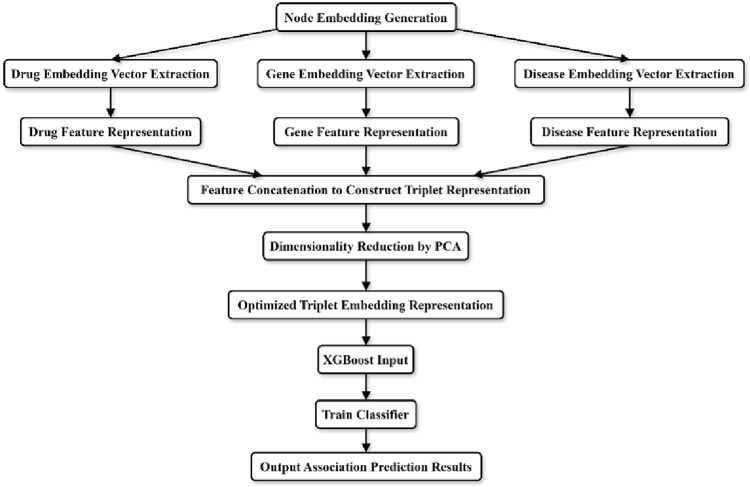
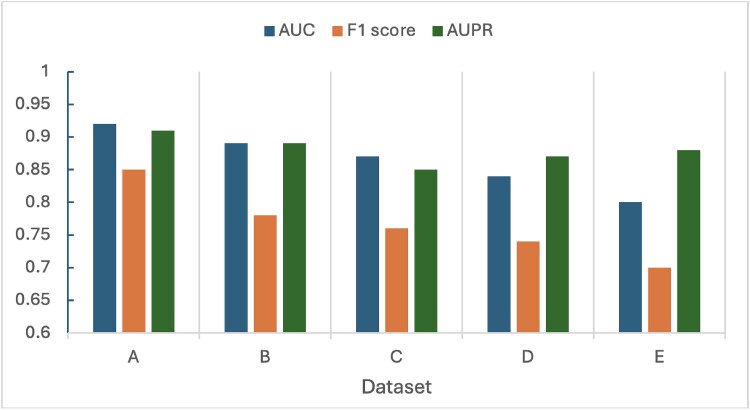
The potential association data between drugs, genes, and diseases is sparse and complex. Existing models find it difficult to effectively handle the problem of heterogeneous relationships and multi-source data fusion simultaneously, resulting in limited accuracy and generalization of association prediction. To address this problem, we propose a fusion method of relational graph convolutional network (R-GCN) and eXtreme Gradient Boosting (XGBoost). First, a heterogeneous graph containing drug, gene, and disease nodes and their relationships is constructed. The features of different types of nodes are aggregated and represented by R-GCN to generate high-quality node embeddings. Then, the embedded features of the drug-gene-disease triples are input into the XGBoost model for training to achieve the association prediction task. The findings demonstrate that the model's area under the curve reaches 0.92, and the F1 score reaches 0.85, indicating strong predictive ability. This method solves the problem of association prediction in complex biological networks and brings new technological support for precision medicine.
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


