{"title":"Uncertainty-Informed Screening for Safer Solvents Used in the Synthesis of Perovskites via Language Models","authors":"Arpan Mukherjee, Deepesh Giri and Krishna Rajan*, ","doi":"10.1021/acs.jcim.5c00612","DOIUrl":null,"url":null,"abstract":"<p >Automated data curation for niche scientific topics, where data quality and contextual accuracy are paramount, poses significant challenges. Bidirectional contextual models such as BERT and ELMo excel in contextual understanding and determinism. However, they are constrained by their narrower training corpora and inability to synthesize information across fragmented or sparse contexts. Conversely, autoregressive generative models like GPT can synthesize dispersed information by leveraging broader contextual knowledge and yet often generate plausible but incorrect (“hallucinated”) information. To address these complementary limitations, we propose an ensemble approach that combines the deterministic precision of BERT/ELMo with the contextual depth of GPT. We have developed a hierarchical knowledge extraction framework to identify perovskites and their associated solvents in perovskite synthesis, progressing from broad topics to narrower details using two complementary methods. The first method leverages deterministic models like BERT/ELMo for precise entity extraction, while the second employs GPT for broader contextual synthesis and generalization. Outputs from both methods are validated through structure-matching and entity normalization, ensuring consistency and traceability. In the absence of benchmark data sets for this domain, we hold out a subset of papers for manual verification to serve as a reference set for tuning the rules for entity normalization. This enables quantitative evaluation of model precision, recall, and structural adherence while also providing a grounded estimate of model confidence. By intersecting the outputs from both methods, we generate a list of solvents with maximum confidence, combining precision with contextual depth to ensure accuracy and reliability. This approach increases precision at the expense of recall─a trade-off we accept given that, in high-trust scientific applications, minimizing hallucinations is often more critical than achieving full coverage, especially when downstream reliability is paramount. As a case study, the curated data set is used to predict the endocrine-disrupting (ED) potential of solvents with a pretrained deep learning model. Recognizing that machine learning models may not be trained on niche data sets such as perovskite-related solvents, we have quantified epistemic uncertainty using Shannon entropy. This measure evaluates the confidence of the ML model predictions, independent of uncertainties in the NLP-based data curation process, and identifies high-risk solvents requiring further validation. Additionally, the manual verification pipeline addresses ethical considerations around trust, structure, and transparency in AI-curated data sets.</p>","PeriodicalId":44,"journal":{"name":"Journal of Chemical Information and Modeling ","volume":"65 15","pages":"7901–7918"},"PeriodicalIF":5.3000,"publicationDate":"2025-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemical Information and Modeling ","FirstCategoryId":"92","ListUrlMain":"https://pubs.acs.org/doi/10.1021/acs.jcim.5c00612","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
引用次数: 0
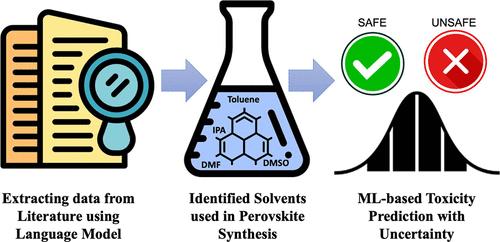
Abstract
Automated data curation for niche scientific topics, where data quality and contextual accuracy are paramount, poses significant challenges. Bidirectional contextual models such as BERT and ELMo excel in contextual understanding and determinism. However, they are constrained by their narrower training corpora and inability to synthesize information across fragmented or sparse contexts. Conversely, autoregressive generative models like GPT can synthesize dispersed information by leveraging broader contextual knowledge and yet often generate plausible but incorrect (“hallucinated”) information. To address these complementary limitations, we propose an ensemble approach that combines the deterministic precision of BERT/ELMo with the contextual depth of GPT. We have developed a hierarchical knowledge extraction framework to identify perovskites and their associated solvents in perovskite synthesis, progressing from broad topics to narrower details using two complementary methods. The first method leverages deterministic models like BERT/ELMo for precise entity extraction, while the second employs GPT for broader contextual synthesis and generalization. Outputs from both methods are validated through structure-matching and entity normalization, ensuring consistency and traceability. In the absence of benchmark data sets for this domain, we hold out a subset of papers for manual verification to serve as a reference set for tuning the rules for entity normalization. This enables quantitative evaluation of model precision, recall, and structural adherence while also providing a grounded estimate of model confidence. By intersecting the outputs from both methods, we generate a list of solvents with maximum confidence, combining precision with contextual depth to ensure accuracy and reliability. This approach increases precision at the expense of recall─a trade-off we accept given that, in high-trust scientific applications, minimizing hallucinations is often more critical than achieving full coverage, especially when downstream reliability is paramount. As a case study, the curated data set is used to predict the endocrine-disrupting (ED) potential of solvents with a pretrained deep learning model. Recognizing that machine learning models may not be trained on niche data sets such as perovskite-related solvents, we have quantified epistemic uncertainty using Shannon entropy. This measure evaluates the confidence of the ML model predictions, independent of uncertainties in the NLP-based data curation process, and identifies high-risk solvents requiring further validation. Additionally, the manual verification pipeline addresses ethical considerations around trust, structure, and transparency in AI-curated data sets.
期刊介绍:
The Journal of Chemical Information and Modeling publishes papers reporting new methodology and/or important applications in the fields of chemical informatics and molecular modeling. Specific topics include the representation and computer-based searching of chemical databases, molecular modeling, computer-aided molecular design of new materials, catalysts, or ligands, development of new computational methods or efficient algorithms for chemical software, and biopharmaceutical chemistry including analyses of biological activity and other issues related to drug discovery.
Astute chemists, computer scientists, and information specialists look to this monthly’s insightful research studies, programming innovations, and software reviews to keep current with advances in this integral, multidisciplinary field.
As a subscriber you’ll stay abreast of database search systems, use of graph theory in chemical problems, substructure search systems, pattern recognition and clustering, analysis of chemical and physical data, molecular modeling, graphics and natural language interfaces, bibliometric and citation analysis, and synthesis design and reactions databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


