Deep Hybrid Manifold Network with joint metric learning for image set classification
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
Abstract
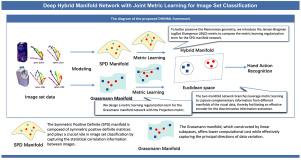
Many studies have shown that complex visual data exhibit non-linear and non-Euclidean characteristics. How to find an intrinsic and low-dimensional representation for non-linear visual data is crucial for image set classification. Due to the powerful data interpretation of deep neural networks and the intrinsic structural exploitation of manifold learning, deep Riemannian neural networks have demonstrated excellent performance on solving the non-linear and non-Euclidean data. However, on the one hand, deep Riemannian neural networks usually focus on exploring the intrinsic structure of the single manifold, while complex visual data may contain multiple potential intrinsic structures. On the other hand, the single cross-entropy is usually adopted as the sole loss function, which may lose discriminative metric information. In this paper, we propose a deep Riemannian neural network by fusing Symmetric Positive Definite (SPD) and Grassmann manifolds to explore multiple intrinsic structures in complex visual data. We innovatively employ the Jensen–Bregman LogDet Divergence and Projection metric to construct two metric learning regularization terms over SPD and Grassmann manifold networks respectively, which capture the intra-class and inter-class data distributions. Subsequently, the regularization terms corresponding to different manifolds are jointly learned in conjunction with the cross-entropy loss function to fuse multiple loss information. Extensive experiments are conducted on expression recognition, gesture recognition, and action recognition tasks. Experimental results demonstrate the superior performance of the proposed Riemannian network.
基于联合度量学习的深度混合流形网络图像集分类
许多研究表明,复杂的视觉数据具有非线性和非欧几里得特征。如何找到非线性视觉数据的内在低维表示是图像集分类的关键。由于深度神经网络强大的数据解释能力和流形学习的内在结构利用,深度黎曼神经网络在求解非线性和非欧几里得数据方面表现出优异的性能。然而,一方面,深度黎曼神经网络通常侧重于探索单个流形的内在结构,而复杂的视觉数据可能包含多个潜在的内在结构。另一方面,通常采用单一交叉熵作为唯一的损失函数,这可能会丢失判别度量信息。本文提出了一种融合对称正定流形和格拉斯曼流形的深度黎曼神经网络,用于探索复杂视觉数据中的多重内在结构。我们创新地采用Jensen-Bregman LogDet散度和投影度量分别在SPD和Grassmann流形网络上构造了两个度量学习正则化项,它们捕获了类内和类间数据分布。然后,结合交叉熵损失函数,共同学习不同流形对应的正则化项,融合多个损失信息。在表情识别、手势识别和动作识别任务上进行了大量的实验。实验结果证明了所提黎曼网络的优越性能。
本文章由计算机程序翻译,如有差异,请以英文原文为准。
求助全文
约1分钟内获得全文
求助全文
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


