Taisuke Sato, Emily D Grussing, Ruchi Patel, Jessica Ridgway, Joji Suzuki, Benjamin Sweigart, Robert Miller, Alysse G Wurcel
{"title":"Natural Language Processing for Identification of Hospitalized People Who Use Drugs: Cohort Study.","authors":"Taisuke Sato, Emily D Grussing, Ruchi Patel, Jessica Ridgway, Joji Suzuki, Benjamin Sweigart, Robert Miller, Alysse G Wurcel","doi":"10.2196/63147","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>People who use drugs (PWUD) are at heightened risk of severe injection-related infections. Current research relies on billing codes to identify PWUD-a methodology with suboptimal accuracy that may underestimate the economic, racial, and ethnic diversity of hospitalized PWUD.</p><p><strong>Objective: </strong>The goal of this study is to examine the impact of natural language processing (NLP) on enhancing identification of PWUD in electronic medical records, with a specific focus on determining improved systems of identifying populations who may previously been missed, including people who have low income or those from racially and ethnically minoritized populations.</p><p><strong>Methods: </strong>Health informatics specialists assisted in querying a cohort of likely PWUD hospital admissions at Tufts Medical Center between 2020-2022 using the following criteria: (1) ICD-10 codes indicative of drug use, (2) positive drug toxicology results, (3) prescriptions for medications for opioid use disorder, and (4) applying NLP-detected presence of \"token\" keywords in the electronic medical records likely indicative of the patient being a PWUD. Hospital admissions were split into two groups: highly documented (all four criteria present) and minimally documented (NLP-only). These groups were examined to assess the impact of race, ethnicity, and social vulnerability index. With chart review as the \"gold standard,\" the positive predictive value was calculated.</p><p><strong>Results: </strong>The cohort included 4548 hospitalization admissions, with broad heterogeneity in how people entered the cohort and subcohorts; a total of 288 hospital admissions entered the cohort through NLP token presence alone. NLP demonstrated a 54% positive predictive value, outperforming biomarkers, prescription for medications for opioid use disorder, and ICD codes in identifying hospitalizations of PWUD. Additionally, NLP significantly enhanced these methods when integrated into the identification algorithm. The study also found that people from racially and ethnically minoritized communities and those with lower social vulnerability index were significantly more likely to have lower rates of PWUD-related documentation.</p><p><strong>Conclusions: </strong>NLP proved effective in identifying hospitalizations of PWUD, surpassing traditional methods. While further refinement is needed, NLP shows promising potential in minimizing health care disparities.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e63147"},"PeriodicalIF":2.0000,"publicationDate":"2025-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12294639/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/63147","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: People who use drugs (PWUD) are at heightened risk of severe injection-related infections. Current research relies on billing codes to identify PWUD-a methodology with suboptimal accuracy that may underestimate the economic, racial, and ethnic diversity of hospitalized PWUD.
Objective: The goal of this study is to examine the impact of natural language processing (NLP) on enhancing identification of PWUD in electronic medical records, with a specific focus on determining improved systems of identifying populations who may previously been missed, including people who have low income or those from racially and ethnically minoritized populations.
Methods: Health informatics specialists assisted in querying a cohort of likely PWUD hospital admissions at Tufts Medical Center between 2020-2022 using the following criteria: (1) ICD-10 codes indicative of drug use, (2) positive drug toxicology results, (3) prescriptions for medications for opioid use disorder, and (4) applying NLP-detected presence of "token" keywords in the electronic medical records likely indicative of the patient being a PWUD. Hospital admissions were split into two groups: highly documented (all four criteria present) and minimally documented (NLP-only). These groups were examined to assess the impact of race, ethnicity, and social vulnerability index. With chart review as the "gold standard," the positive predictive value was calculated.
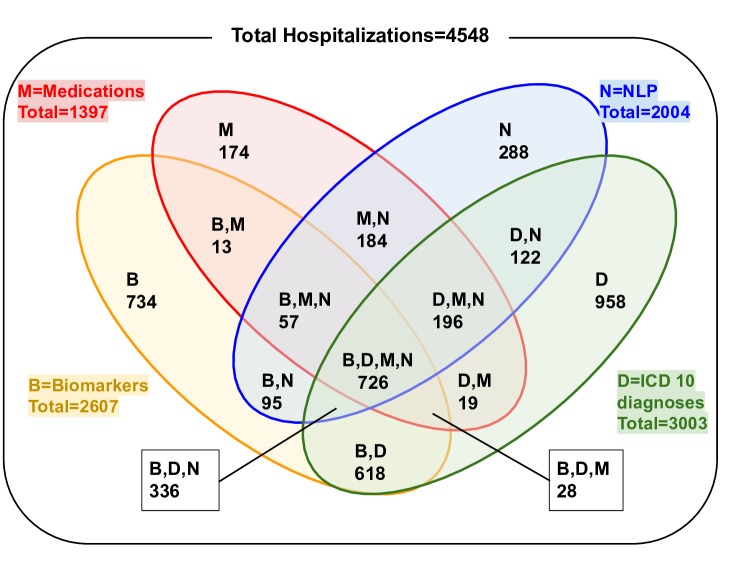
Results: The cohort included 4548 hospitalization admissions, with broad heterogeneity in how people entered the cohort and subcohorts; a total of 288 hospital admissions entered the cohort through NLP token presence alone. NLP demonstrated a 54% positive predictive value, outperforming biomarkers, prescription for medications for opioid use disorder, and ICD codes in identifying hospitalizations of PWUD. Additionally, NLP significantly enhanced these methods when integrated into the identification algorithm. The study also found that people from racially and ethnically minoritized communities and those with lower social vulnerability index were significantly more likely to have lower rates of PWUD-related documentation.
Conclusions: NLP proved effective in identifying hospitalizations of PWUD, surpassing traditional methods. While further refinement is needed, NLP shows promising potential in minimizing health care disparities.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


