ChulHyoung Park, Min Ho An, Gyubeom Hwang, Rae Woong Park, Juho An
{"title":"Clinical Performance and Communication Skills of ChatGPT Versus Physicians in Emergency Medicine: Simulated Patient Study.","authors":"ChulHyoung Park, Min Ho An, Gyubeom Hwang, Rae Woong Park, Juho An","doi":"10.2196/68409","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Emergency medicine can benefit from artificial intelligence (AI) due to its unique challenges, such as high patient volume and the need for urgent interventions. However, it remains difficult to assess the applicability of AI systems to real-world emergency medicine practice, which requires not only medical knowledge but also adaptable problem-solving and effective communication skills.</p><p><strong>Objective: </strong>We aimed to evaluate ChatGPT's (OpenAI) performance in comparison to human doctors in simulated emergency medicine settings, using the framework of clinical performance examination and written examinations.</p><p><strong>Methods: </strong>In total, 12 human doctors were recruited to represent the medical professionals. Both ChatGPT and the human doctors were instructed to manage each case like real clinical settings with 12 simulated patients. After the clinical performance examination sessions, the conversation records were evaluated by an emergency medicine professor on history taking, clinical accuracy, and empathy on a 5-point Likert scale. Simulated patients completed a 5-point scale survey including overall comprehensibility, credibility, and concern reduction for each case. In addition, they evaluated whether the doctor they interacted with was similar to a human doctor. An additional evaluation was performed using vignette-based written examinations to assess diagnosis, investigation, and treatment planning. The mean scores from ChatGPT were then compared with those of the human doctors.</p><p><strong>Results: </strong>ChatGPT scored significantly higher than the physicians in both history-taking (mean score 3.91, SD 0.67 vs mean score 2.67, SD 0.78, P<.001) and empathy (mean score 4.50, SD 0.67 vs mean score 1.75, SD 0.62, P<.001). However, there was no significant difference in clinical accuracy. In the survey conducted with simulated patients, ChatGPT scored higher for concern reduction (mean score 4.33, SD 0.78 vs mean score 3.58, SD 0.90, P=.04). For comprehensibility and credibility, ChatGPT showed better performance, but the difference was not significant. In the similarity assessment score, no significant difference was observed (mean score 3.50, SD 1.78 vs mean score 3.25, SD 1.86, P=.71).</p><p><strong>Conclusions: </strong>ChatGPT's performance highlights its potential as a valuable adjunct in emergency medicine, demonstrating comparable proficiency in knowledge application, efficiency, and empathetic patient interaction. These results suggest that a collaborative health care model, integrating AI with human expertise, could enhance patient care and outcomes.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e68409"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12289221/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/68409","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Emergency medicine can benefit from artificial intelligence (AI) due to its unique challenges, such as high patient volume and the need for urgent interventions. However, it remains difficult to assess the applicability of AI systems to real-world emergency medicine practice, which requires not only medical knowledge but also adaptable problem-solving and effective communication skills.
Objective: We aimed to evaluate ChatGPT's (OpenAI) performance in comparison to human doctors in simulated emergency medicine settings, using the framework of clinical performance examination and written examinations.
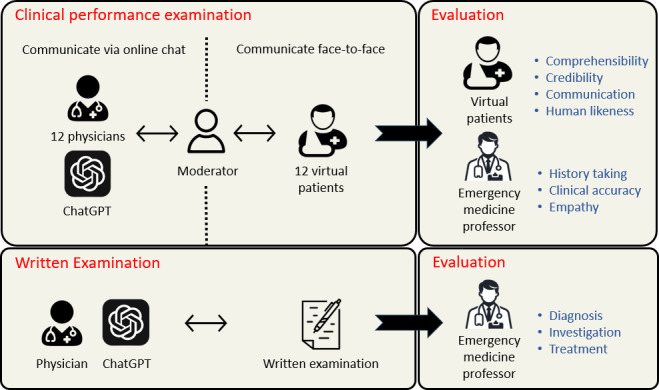
Methods: In total, 12 human doctors were recruited to represent the medical professionals. Both ChatGPT and the human doctors were instructed to manage each case like real clinical settings with 12 simulated patients. After the clinical performance examination sessions, the conversation records were evaluated by an emergency medicine professor on history taking, clinical accuracy, and empathy on a 5-point Likert scale. Simulated patients completed a 5-point scale survey including overall comprehensibility, credibility, and concern reduction for each case. In addition, they evaluated whether the doctor they interacted with was similar to a human doctor. An additional evaluation was performed using vignette-based written examinations to assess diagnosis, investigation, and treatment planning. The mean scores from ChatGPT were then compared with those of the human doctors.
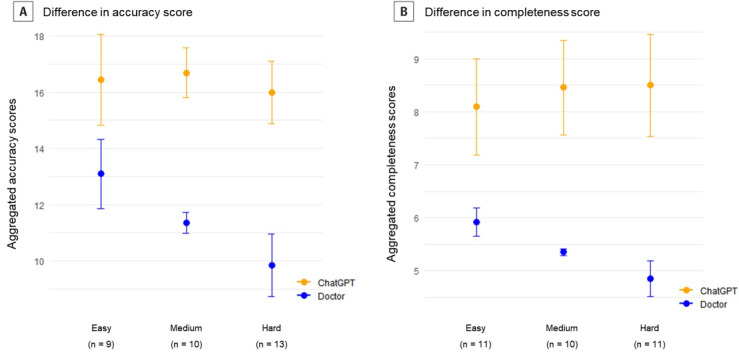
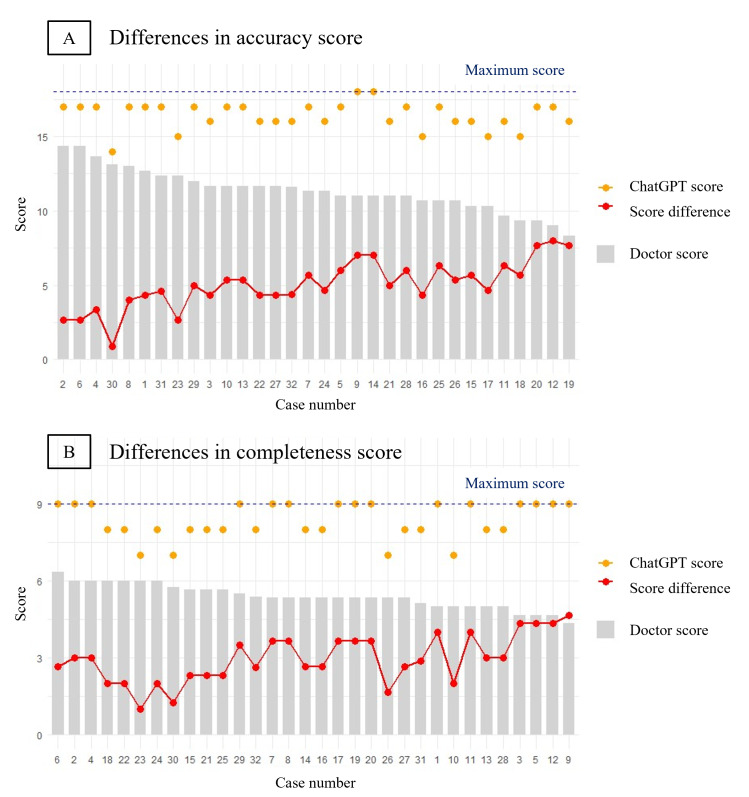
Results: ChatGPT scored significantly higher than the physicians in both history-taking (mean score 3.91, SD 0.67 vs mean score 2.67, SD 0.78, P<.001) and empathy (mean score 4.50, SD 0.67 vs mean score 1.75, SD 0.62, P<.001). However, there was no significant difference in clinical accuracy. In the survey conducted with simulated patients, ChatGPT scored higher for concern reduction (mean score 4.33, SD 0.78 vs mean score 3.58, SD 0.90, P=.04). For comprehensibility and credibility, ChatGPT showed better performance, but the difference was not significant. In the similarity assessment score, no significant difference was observed (mean score 3.50, SD 1.78 vs mean score 3.25, SD 1.86, P=.71).
Conclusions: ChatGPT's performance highlights its potential as a valuable adjunct in emergency medicine, demonstrating comparable proficiency in knowledge application, efficiency, and empathetic patient interaction. These results suggest that a collaborative health care model, integrating AI with human expertise, could enhance patient care and outcomes.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


