Jordon Junyang Kho, Shangzheng Song, Samuel Ming Xuan Tan, Nur Hikmah Fitriyah, Matheus Calvin Lokadjaja, Jie Yin Yee, Zixu Yang, Eric Yu Hai Chen, Jimmy Lee, Wilson Wen Bin Goh
{"title":"Leveraging computational linguistics and machine learning for detection of ultra-high risk of mental health disorders in youths.","authors":"Jordon Junyang Kho, Shangzheng Song, Samuel Ming Xuan Tan, Nur Hikmah Fitriyah, Matheus Calvin Lokadjaja, Jie Yin Yee, Zixu Yang, Eric Yu Hai Chen, Jimmy Lee, Wilson Wen Bin Goh","doi":"10.1038/s41537-025-00649-3","DOIUrl":null,"url":null,"abstract":"<p><p>Mental illnesses often manifest through behavioral changes, with speech serving as a key medium for expressing thoughts and emotions. The use of computational linguistics on speech data in mental illnesses is a promising approach to uncover objective biomarkers for the early detection of mental illnesses. This study analyzed speech transcripts from 80 youths at ultra-high risk of psychosis (UHR) and 329 healthy controls, examining text features such as sentiment variability, cohesion, lexical sophistication, morphology, syntactic sophistication, and lexical diversity. Factor analysis revealed five key linguistic themes: Sentiment Intensity and Variability, Linguistic Register Alignment, Phonographic Uniqueness and Recognizability, Morphological Complexity and Imageability, and Lexical Richness and Typicalness. Regression analysis indicated UHR speech is characterized by diminished sentiment variability (β = -0.07), deviation from linguistic registers (β = -0.16), fewer phonographic neighbors (β = -0.11), lower morphological complexity (β = -0.36), and more predictable lexical structures (β = 0.05). Optimized machine learning (ML) models trained on Boruta-selected features achieved a mean AUC of 0.70. Our findings highlight the potential of sentiment and linguistic analyses in speech for training ML models to aid in early detection and monitoring of mental health conditions.</p>","PeriodicalId":74758,"journal":{"name":"Schizophrenia (Heidelberg, Germany)","volume":"11 1","pages":"98"},"PeriodicalIF":4.1000,"publicationDate":"2025-07-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12264269/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Schizophrenia (Heidelberg, Germany)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1038/s41537-025-00649-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PSYCHIATRY","Score":null,"Total":0}
引用次数: 0
Abstract
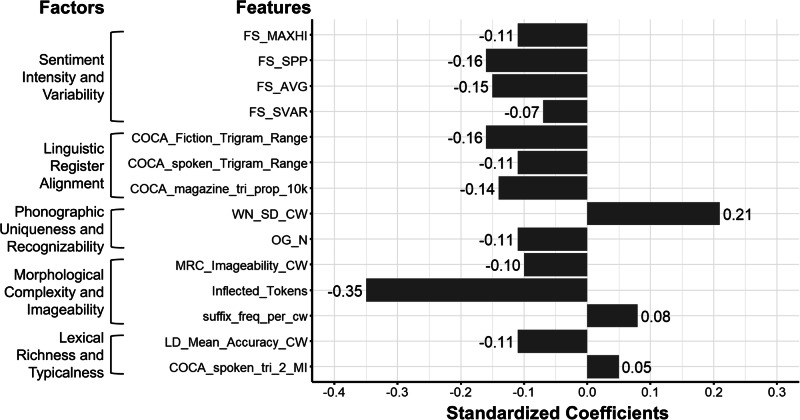
Mental illnesses often manifest through behavioral changes, with speech serving as a key medium for expressing thoughts and emotions. The use of computational linguistics on speech data in mental illnesses is a promising approach to uncover objective biomarkers for the early detection of mental illnesses. This study analyzed speech transcripts from 80 youths at ultra-high risk of psychosis (UHR) and 329 healthy controls, examining text features such as sentiment variability, cohesion, lexical sophistication, morphology, syntactic sophistication, and lexical diversity. Factor analysis revealed five key linguistic themes: Sentiment Intensity and Variability, Linguistic Register Alignment, Phonographic Uniqueness and Recognizability, Morphological Complexity and Imageability, and Lexical Richness and Typicalness. Regression analysis indicated UHR speech is characterized by diminished sentiment variability (β = -0.07), deviation from linguistic registers (β = -0.16), fewer phonographic neighbors (β = -0.11), lower morphological complexity (β = -0.36), and more predictable lexical structures (β = 0.05). Optimized machine learning (ML) models trained on Boruta-selected features achieved a mean AUC of 0.70. Our findings highlight the potential of sentiment and linguistic analyses in speech for training ML models to aid in early detection and monitoring of mental health conditions.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


