Olivia J Veatch, Jomol Mathew, Shira Rockowitz, Dustin Baldridge, Alyssa Wetzel, Maria Niarchou, Megan Clarke, Prabhu Shankar, Suma Shankar, Julie S Cohen, Kendell German, Seth Berger, Angela Sellitto, Inez Y Oh, Rashi Raizada, Piotr Sliz, Selvin Soby, Mihailo Kaplarevic, Dan Doherty, Andrea Gropman, Constance Smith-Hicks, Jeffrey L Neul, Virginia Lanzotti, Benjamin Darbro, Qiang Chang, Mustafa Sahin, Maya Chopra
{"title":"Finding buried genetic test results in the electronic health record is inefficient and variable across institutions.","authors":"Olivia J Veatch, Jomol Mathew, Shira Rockowitz, Dustin Baldridge, Alyssa Wetzel, Maria Niarchou, Megan Clarke, Prabhu Shankar, Suma Shankar, Julie S Cohen, Kendell German, Seth Berger, Angela Sellitto, Inez Y Oh, Rashi Raizada, Piotr Sliz, Selvin Soby, Mihailo Kaplarevic, Dan Doherty, Andrea Gropman, Constance Smith-Hicks, Jeffrey L Neul, Virginia Lanzotti, Benjamin Darbro, Qiang Chang, Mustafa Sahin, Maya Chopra","doi":"10.1177/26330040251356521","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The absence of standardized approaches for handling genetic test results in electronic health records (EHRs), combined with a lack of diagnostic codes for most rare disorders, hinders accurate and timely identification of patients with rare genetic variants. This impedes access to research opportunities and genomic-driven care. To reduce the diagnostic odyssey, identify research-eligible subjects, and ultimately enhance patient care, it is critical to optimize approaches to retrieve genetic results.</p><p><strong>Objectives: </strong>To characterize resource requirements, yield, and biases among methods for identifying and retrieving genetic test results across 11 Intellectual and Developmental Disability Research Centers (IDDRC).</p><p><strong>Design: </strong>A survey was used to collect details from the authors on approaches to identify EHRs from patients who had genetic testing and variants of interest were reported; surveys were completed in 2022.</p><p><strong>Methods: </strong>Strengths and limitations in approaches to identify and retrieve genetic test results conducted from the implementation of EHR systems were evaluated. A standard template was used to collect genetic testing storage formats, methods to identify patients with rare disease variants, estimates of time/cost, nature of accessed data, method-specific bias in types of American College of Medical Genetics and Genomics classified variants identified. When possible, precision when performing gene name searches in the EHR was calculated.</p><p><strong>Results: </strong>Four approaches were used: (1) manual searches, reviews, and extractions, (2) natural language processing software-aided manual reviews and extractions, (3) custom databases via testing lab collaborations, and (4) testing EHR vendor-designed genomics modules. The fully manual approach required minimal infrastructure and allowed access to clinical notes but missed variants of unknown clinical significance. Precision for gene name matches based on searches of 59 genes was 0.16. Natural language processing software minimized effort but required considerable informatics support. Custom databases and EHR vendor modules necessitated substantial computational support; however, genetic testing results retrieval was efficient.</p><p><strong>Conclusion: </strong>Leveraging the IDDRC network, we found that methods to store, search and extract genetic testing results vary widely, especially regarding older test results, and have distinct benefits and limitations. Limitations are best addressed through practice guidelines that standardize storage and retrieval of genetic test results to facilitate efficient identification of research eligible subjects and genomic-informed patient care.</p>","PeriodicalId":75218,"journal":{"name":"Therapeutic advances in rare disease","volume":"6 ","pages":"26330040251356521"},"PeriodicalIF":0.0000,"publicationDate":"2025-07-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12254648/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Therapeutic advances in rare disease","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/26330040251356521","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The absence of standardized approaches for handling genetic test results in electronic health records (EHRs), combined with a lack of diagnostic codes for most rare disorders, hinders accurate and timely identification of patients with rare genetic variants. This impedes access to research opportunities and genomic-driven care. To reduce the diagnostic odyssey, identify research-eligible subjects, and ultimately enhance patient care, it is critical to optimize approaches to retrieve genetic results.
Objectives: To characterize resource requirements, yield, and biases among methods for identifying and retrieving genetic test results across 11 Intellectual and Developmental Disability Research Centers (IDDRC).
Design: A survey was used to collect details from the authors on approaches to identify EHRs from patients who had genetic testing and variants of interest were reported; surveys were completed in 2022.
Methods: Strengths and limitations in approaches to identify and retrieve genetic test results conducted from the implementation of EHR systems were evaluated. A standard template was used to collect genetic testing storage formats, methods to identify patients with rare disease variants, estimates of time/cost, nature of accessed data, method-specific bias in types of American College of Medical Genetics and Genomics classified variants identified. When possible, precision when performing gene name searches in the EHR was calculated.
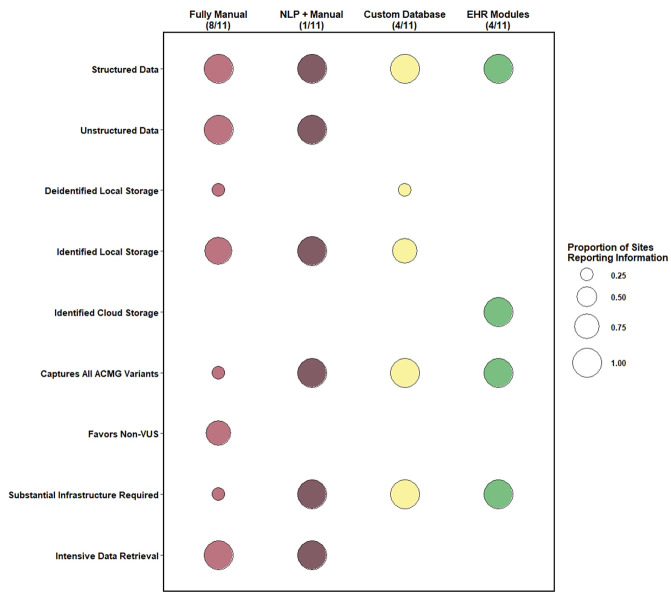
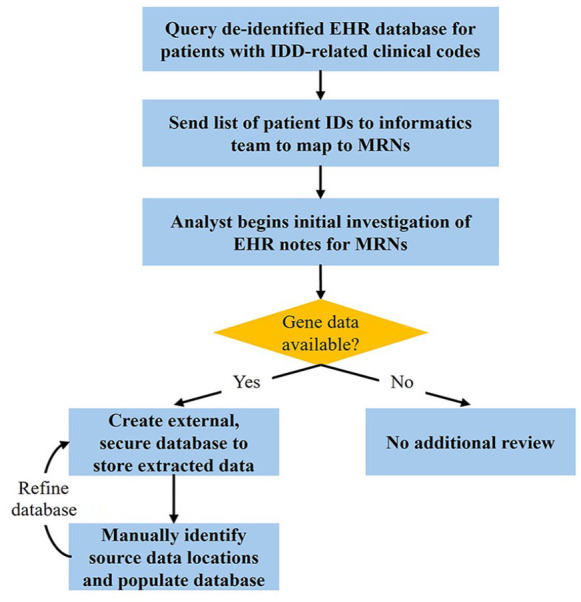
Results: Four approaches were used: (1) manual searches, reviews, and extractions, (2) natural language processing software-aided manual reviews and extractions, (3) custom databases via testing lab collaborations, and (4) testing EHR vendor-designed genomics modules. The fully manual approach required minimal infrastructure and allowed access to clinical notes but missed variants of unknown clinical significance. Precision for gene name matches based on searches of 59 genes was 0.16. Natural language processing software minimized effort but required considerable informatics support. Custom databases and EHR vendor modules necessitated substantial computational support; however, genetic testing results retrieval was efficient.
Conclusion: Leveraging the IDDRC network, we found that methods to store, search and extract genetic testing results vary widely, especially regarding older test results, and have distinct benefits and limitations. Limitations are best addressed through practice guidelines that standardize storage and retrieval of genetic test results to facilitate efficient identification of research eligible subjects and genomic-informed patient care.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


