{"title":"PangenePro: an automated pipeline for rapid identification and classification of gene family members.","authors":"Kinza Fatima, Haifei Hu, Muhammad Tahir Ul Qamar","doi":"10.1093/bioadv/vbaf159","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>The increasing availability of sequenced and assembled plant genomes in public databases has led to a surge in genome-wide identification (GWI) studies of gene families. However, previous studies are often single-reference genome-based, limiting their ability to capture intraspecific genetic diversity. Further, manual identification from multiple genomes is labor-intensive and time-consuming.</p><p><strong>Results: </strong>Here, we present PangenePro, a fully automated pipeline using Python and R scripting, implemented in the Linux environment, designed to identify and classify gene family members across multiple genomes simultaneously. This pipeline integrates sequence alignment using BLAST, domain validation through InterProScan, and orthologous clustering to classify the identified genes into core, dispensable, and unique pangenes sets. PangenePro was tested using five Arabidopsis thaliana, three Arachis and rice, and five Barley genomes, identifying a number of members comparable to those in previously reported studies. These results demonstrate the accuracy and efficiency of this method for gene family identification and classification in diverse and complex genomes. Moreover, its rapid nature enables comprehensive capture of intraspecific diversity and yields valuable candidate genes for further functional and plant breeding studies.</p><p><strong>Availability and implementation: </strong>The PangenePro is freely available at GitHub DOI: https://github.com/kinza111/PangenePro.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf159"},"PeriodicalIF":2.8000,"publicationDate":"2025-07-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12255874/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf159","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: The increasing availability of sequenced and assembled plant genomes in public databases has led to a surge in genome-wide identification (GWI) studies of gene families. However, previous studies are often single-reference genome-based, limiting their ability to capture intraspecific genetic diversity. Further, manual identification from multiple genomes is labor-intensive and time-consuming.
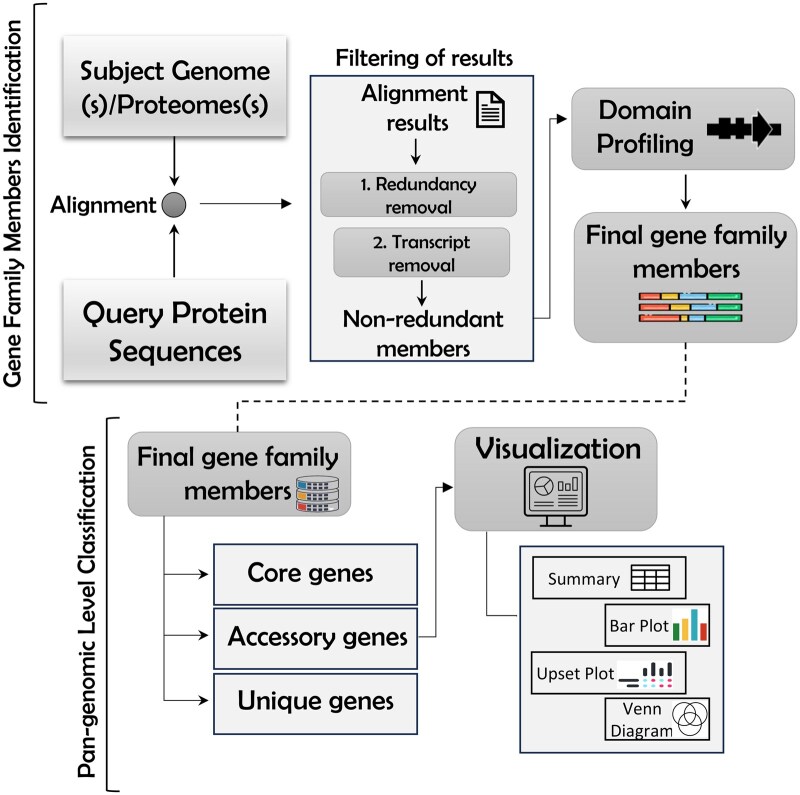
Results: Here, we present PangenePro, a fully automated pipeline using Python and R scripting, implemented in the Linux environment, designed to identify and classify gene family members across multiple genomes simultaneously. This pipeline integrates sequence alignment using BLAST, domain validation through InterProScan, and orthologous clustering to classify the identified genes into core, dispensable, and unique pangenes sets. PangenePro was tested using five Arabidopsis thaliana, three Arachis and rice, and five Barley genomes, identifying a number of members comparable to those in previously reported studies. These results demonstrate the accuracy and efficiency of this method for gene family identification and classification in diverse and complex genomes. Moreover, its rapid nature enables comprehensive capture of intraspecific diversity and yields valuable candidate genes for further functional and plant breeding studies.
Availability and implementation: The PangenePro is freely available at GitHub DOI: https://github.com/kinza111/PangenePro.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


