Rory Davidson, Will Hardman, Guy Amit, Yonatan Bilu, Vincenzo Della Mea, Aleksandr Galaida, Irena Girshovitz, Mikhail Kulyabin, Mihai Horia Popescu, Kevin Roitero, Gleb Sokolov, Chen Yanover
{"title":"SNOMED CT entity linking challenge.","authors":"Rory Davidson, Will Hardman, Guy Amit, Yonatan Bilu, Vincenzo Della Mea, Aleksandr Galaida, Irena Girshovitz, Mikhail Kulyabin, Mihai Horia Popescu, Kevin Roitero, Gleb Sokolov, Chen Yanover","doi":"10.1093/jamia/ocaf104","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This paper presents the results from a competition challenging participants to develop entity linking models using a subset of annotated MIMIC-IV-Note data and the SNOMED CT Terminology.</p><p><strong>Materials and methods: </strong>As a basis for this work, a large set of 74 808 annotations was curated across 272 discharge notes spanning 6624 unique clinical concepts. Submissions were evaluated using the mean Intersection-over-Union metric, evaluated at the character level with the 3 best performing solutions awarded a cash prize.</p><p><strong>Results: </strong>The winning solutions employed contrasting approaches: a dictionary-based method, an encoder-based method, and a decoder-based method.</p><p><strong>Discussion: </strong>Our analysis reveals that concept frequency in training data significantly impacts model performance, with rare concepts proving particularly challenging. High concept entropy and annotation ambiguity were also associated with decreased performance.</p><p><strong>Conclusion: </strong>Findings from this work suggest that future projects should focus on improving entity linking for rare concepts and developing methods to better leverage contextual information when training examples are scarce.</p>","PeriodicalId":50016,"journal":{"name":"Journal of the American Medical Informatics Association","volume":" ","pages":"1397-1406"},"PeriodicalIF":4.6000,"publicationDate":"2025-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12361850/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the American Medical Informatics Association","FirstCategoryId":"91","ListUrlMain":"https://doi.org/10.1093/jamia/ocaf104","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
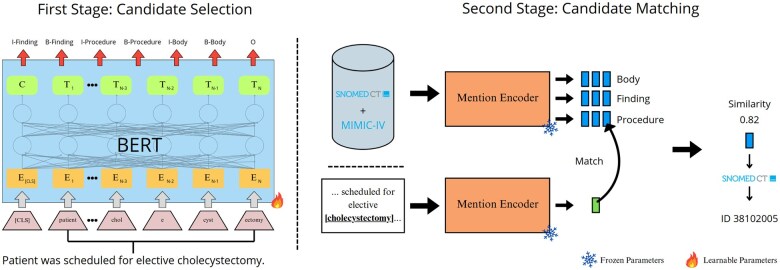
Objective: This paper presents the results from a competition challenging participants to develop entity linking models using a subset of annotated MIMIC-IV-Note data and the SNOMED CT Terminology.
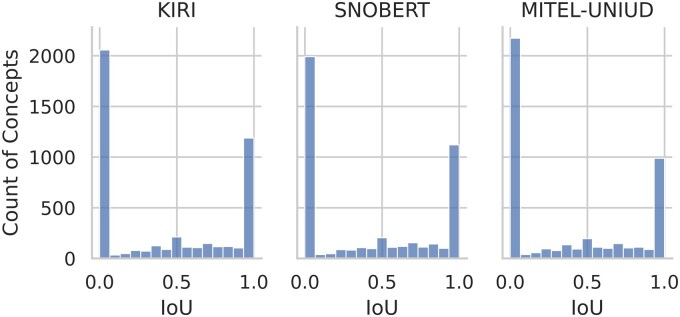
Materials and methods: As a basis for this work, a large set of 74 808 annotations was curated across 272 discharge notes spanning 6624 unique clinical concepts. Submissions were evaluated using the mean Intersection-over-Union metric, evaluated at the character level with the 3 best performing solutions awarded a cash prize.
Results: The winning solutions employed contrasting approaches: a dictionary-based method, an encoder-based method, and a decoder-based method.
Discussion: Our analysis reveals that concept frequency in training data significantly impacts model performance, with rare concepts proving particularly challenging. High concept entropy and annotation ambiguity were also associated with decreased performance.
Conclusion: Findings from this work suggest that future projects should focus on improving entity linking for rare concepts and developing methods to better leverage contextual information when training examples are scarce.
期刊介绍:
JAMIA is AMIA''s premier peer-reviewed journal for biomedical and health informatics. Covering the full spectrum of activities in the field, JAMIA includes informatics articles in the areas of clinical care, clinical research, translational science, implementation science, imaging, education, consumer health, public health, and policy. JAMIA''s articles describe innovative informatics research and systems that help to advance biomedical science and to promote health. Case reports, perspectives and reviews also help readers stay connected with the most important informatics developments in implementation, policy and education.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


