Harry Hochheiser, Jesse Klug, Thomas Mathie, Tom J Pollard, Jesse D Raffa, Stephanie L Ballard, Evamarie A Conrad, Smitha Edakalavan, Allan Joseph, Nader Alnomasy, Sarah Nutman, Veronika Hill, Sumit Kapoor, Eddie Pérez Claudio, Olga V Kravchenko, Ruoting Li, Mehdi Nourelahi, Jenny Diaz, W Michael Taylor, Sydney R Rooney, Maeve Woeltje, Leo Anthony Celi, Christopher M Horvat
{"title":"Raising awareness of potential biases in medical machine learning: Experience from a Datathon.","authors":"Harry Hochheiser, Jesse Klug, Thomas Mathie, Tom J Pollard, Jesse D Raffa, Stephanie L Ballard, Evamarie A Conrad, Smitha Edakalavan, Allan Joseph, Nader Alnomasy, Sarah Nutman, Veronika Hill, Sumit Kapoor, Eddie Pérez Claudio, Olga V Kravchenko, Ruoting Li, Mehdi Nourelahi, Jenny Diaz, W Michael Taylor, Sydney R Rooney, Maeve Woeltje, Leo Anthony Celi, Christopher M Horvat","doi":"10.1371/journal.pdig.0000932","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>To challenge clinicians and informaticians to learn about potential sources of bias in medical machine learning models through investigation of data and predictions from an open-source severity of illness score.</p><p><strong>Methods: </strong>Over a two-day period (total elapsed time approximately 28 hours), we conducted a datathon that challenged interdisciplinary teams to investigate potential sources of bias in the Global Open Source Severity of Illness Score. Teams were invited to develop hypotheses, to use tools of their choosing to identify potential sources of bias, and to provide a final report.</p><p><strong>Results: </strong>Five teams participated, three of which included both informaticians and clinicians. Most (4/5) used Python for analyses, the remaining team used R. Common analysis themes included relationship of the GOSSIS-1 prediction score with demographics and care related variables; relationships between demographics and outcomes; calibration and factors related to the context of care; and the impact of missingness. Representativeness of the population, differences in calibration and model performance among groups, and differences in performance across hospital settings were identified as possible sources of bias.</p><p><strong>Discussion: </strong>Datathons are a promising approach for challenging developers and users to explore questions relating to unrecognized biases in medical machine learning algorithms.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 7","pages":"e0000932"},"PeriodicalIF":7.7000,"publicationDate":"2025-07-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12250157/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000932","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: To challenge clinicians and informaticians to learn about potential sources of bias in medical machine learning models through investigation of data and predictions from an open-source severity of illness score.
Methods: Over a two-day period (total elapsed time approximately 28 hours), we conducted a datathon that challenged interdisciplinary teams to investigate potential sources of bias in the Global Open Source Severity of Illness Score. Teams were invited to develop hypotheses, to use tools of their choosing to identify potential sources of bias, and to provide a final report.
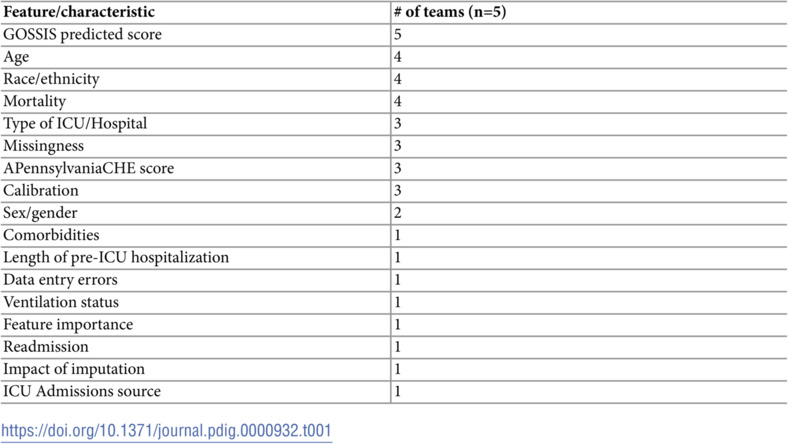
Results: Five teams participated, three of which included both informaticians and clinicians. Most (4/5) used Python for analyses, the remaining team used R. Common analysis themes included relationship of the GOSSIS-1 prediction score with demographics and care related variables; relationships between demographics and outcomes; calibration and factors related to the context of care; and the impact of missingness. Representativeness of the population, differences in calibration and model performance among groups, and differences in performance across hospital settings were identified as possible sources of bias.
Discussion: Datathons are a promising approach for challenging developers and users to explore questions relating to unrecognized biases in medical machine learning algorithms.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


