Jeremy A Balch, Sasank S Desaraju, Victoria J Nolan, Divya Vellanki, Timothy R Buchanan, Lindsey M Brinkley, Yordan Penev, Ahmet Bilgili, Aashay Patel, Corinne E Chatham, David M Vanderbilt, Rayon Uddin, Azra Bihorac, Philip Efron, Tyler J Loftus, Protiva Rahman, Benjamin Shickel
{"title":"Language Models for Multilabel Document Classification of Surgical Concepts in Exploratory Laparotomy Operative Notes: Algorithm Development Study.","authors":"Jeremy A Balch, Sasank S Desaraju, Victoria J Nolan, Divya Vellanki, Timothy R Buchanan, Lindsey M Brinkley, Yordan Penev, Ahmet Bilgili, Aashay Patel, Corinne E Chatham, David M Vanderbilt, Rayon Uddin, Azra Bihorac, Philip Efron, Tyler J Loftus, Protiva Rahman, Benjamin Shickel","doi":"10.2196/71176","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Operative notes are frequently mined for surgical concepts in clinical care, research, quality improvement, and billing, often requiring hours of manual extraction. These notes are typically analyzed at the document level to determine the presence or absence of specific procedures or findings (eg, whether a hand-sewn anastomosis was performed or contamination occurred). Extracting several binary classification labels simultaneously is a multilabel classification problem. Traditional natural language processing approaches-bag-of-words (BoW) and term frequency-inverse document frequency (tf-idf) with linear classifiers-have been used previously for this task but are now being augmented or replaced by large language models (LLMs). However, few studies have examined their utility in surgery.</p><p><strong>Objective: </strong>We developed and evaluated LLMs for the purpose of expediting data extraction from surgical notes.</p><p><strong>Methods: </strong>A total of 388 exploratory laparotomy notes from a single institution were annotated for 21 concepts related to intraoperative findings, intraoperative techniques, and closure techniques. Annotation consistency was measured using the Cohen κ statistic. Data were preprocessed to include only the description of the procedure. We compared the evolution of document classification technologies from BoW and tf-idf to encoder-only (Clinical-Longformer) and decoder-only (Llama 3) transformer models. Multilabel classification performance was evaluated with 5-fold cross-validation with F1-score and hamming loss (HL). We experimented with and without context. Errors were assessed by manual review. Code and implementation instructions may be found on GitHub.</p><p><strong>Results: </strong>The prevalence of labels ranged from 0.05 (colostomy, ileostomy, active bleed from named vessel) to 0.50 (running fascial closure). Llama 3.3 was the overall best-performing model (micro F1-score 0.88, 5-fold range: 0.88-0.89; HL 0.11, 5-fold range: 0.11-0.12). The BoW model (micro F1-score 0.68, 5-fold range: 0.64-0.71; HL 0.14, 5-fold range: 0.13-0.16) and Clinical-Longformer (micro F1-score 0.73, 5-fold range: 0.70-0.74; HL 0.11, 5-fold range: 0.10-0.12) had overall similar performance, with tf-idf models trailing (micro F1-score 0.57, 5-fold range: 0.55-0.59; HL 0.27, 5-fold range: 0.25-0.29). F1-scores varied across concepts in the Llama model, ranging from 0.30 (5-fold range: 0.23-0.39) for class III contamination to 0.92 (5-fold range: 0.98-0.84) for bowel resection. Context enhanced Llama's performance, adding an average of 0.16 improvement to the F1-scores. Error analysis demonstrated semantic nuances and edge cases within operative notes, particularly when patients had references to prior operations in their operative notes or simultaneous operations with other surgical services.</p><p><strong>Conclusions: </strong>Off-the-shelf autoregressive LLMs outperformed fined-tuned, encoder-only transformers and traditional natural language processing techniques in classifying operative notes. Multilabel classification with LLMs may streamline retrospective reviews in surgery, though further refinements are required prior to reliable use in research and quality improvement.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e71176"},"PeriodicalIF":3.8000,"publicationDate":"2025-07-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12266303/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/71176","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Operative notes are frequently mined for surgical concepts in clinical care, research, quality improvement, and billing, often requiring hours of manual extraction. These notes are typically analyzed at the document level to determine the presence or absence of specific procedures or findings (eg, whether a hand-sewn anastomosis was performed or contamination occurred). Extracting several binary classification labels simultaneously is a multilabel classification problem. Traditional natural language processing approaches-bag-of-words (BoW) and term frequency-inverse document frequency (tf-idf) with linear classifiers-have been used previously for this task but are now being augmented or replaced by large language models (LLMs). However, few studies have examined their utility in surgery.
Objective: We developed and evaluated LLMs for the purpose of expediting data extraction from surgical notes.
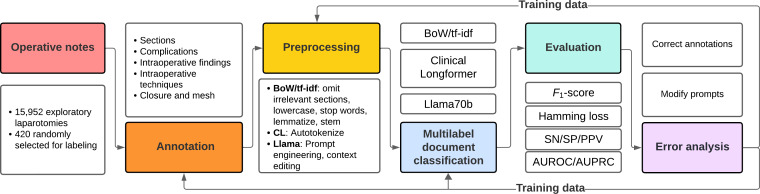
Methods: A total of 388 exploratory laparotomy notes from a single institution were annotated for 21 concepts related to intraoperative findings, intraoperative techniques, and closure techniques. Annotation consistency was measured using the Cohen κ statistic. Data were preprocessed to include only the description of the procedure. We compared the evolution of document classification technologies from BoW and tf-idf to encoder-only (Clinical-Longformer) and decoder-only (Llama 3) transformer models. Multilabel classification performance was evaluated with 5-fold cross-validation with F1-score and hamming loss (HL). We experimented with and without context. Errors were assessed by manual review. Code and implementation instructions may be found on GitHub.
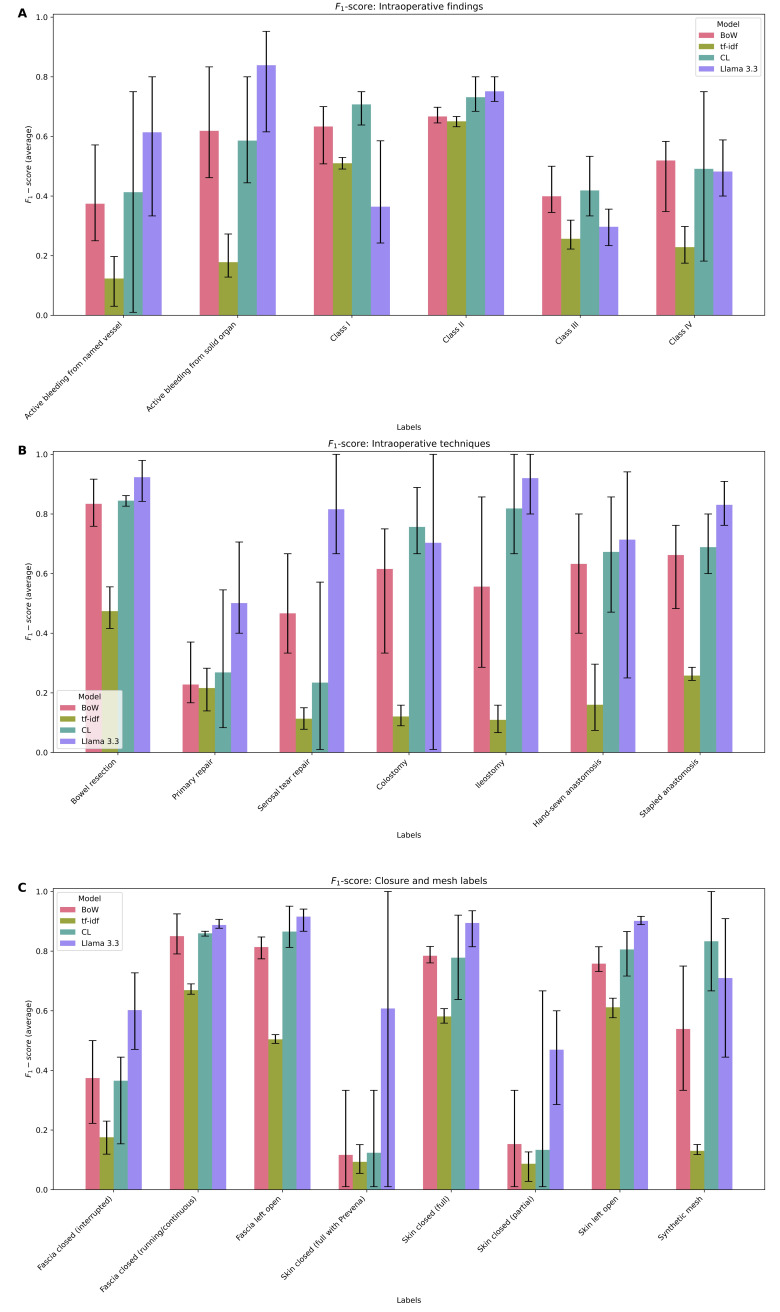
Results: The prevalence of labels ranged from 0.05 (colostomy, ileostomy, active bleed from named vessel) to 0.50 (running fascial closure). Llama 3.3 was the overall best-performing model (micro F1-score 0.88, 5-fold range: 0.88-0.89; HL 0.11, 5-fold range: 0.11-0.12). The BoW model (micro F1-score 0.68, 5-fold range: 0.64-0.71; HL 0.14, 5-fold range: 0.13-0.16) and Clinical-Longformer (micro F1-score 0.73, 5-fold range: 0.70-0.74; HL 0.11, 5-fold range: 0.10-0.12) had overall similar performance, with tf-idf models trailing (micro F1-score 0.57, 5-fold range: 0.55-0.59; HL 0.27, 5-fold range: 0.25-0.29). F1-scores varied across concepts in the Llama model, ranging from 0.30 (5-fold range: 0.23-0.39) for class III contamination to 0.92 (5-fold range: 0.98-0.84) for bowel resection. Context enhanced Llama's performance, adding an average of 0.16 improvement to the F1-scores. Error analysis demonstrated semantic nuances and edge cases within operative notes, particularly when patients had references to prior operations in their operative notes or simultaneous operations with other surgical services.
Conclusions: Off-the-shelf autoregressive LLMs outperformed fined-tuned, encoder-only transformers and traditional natural language processing techniques in classifying operative notes. Multilabel classification with LLMs may streamline retrospective reviews in surgery, though further refinements are required prior to reliable use in research and quality improvement.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


