{"title":"StackGlyEmbed: prediction of N-linked glycosylation sites using protein language models.","authors":"Md Muhaiminul Islam Nafi, M Saifur Rahman","doi":"10.1093/bioadv/vbaf146","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>N-linked glycosylation is one of the most basic post-translational modifications (PTMs) where oligosaccharides covalently bond with Asparagine (N). These are found in the conserved regions like N-X-S or N-X-T where X can be any residue except Proline (P). Prediction of N-linked glycosylation sites has great importance as these PTMs play a vital role in many biological processes and functionalities. Experimental methods, such as mass spectrometry, for detecting N-linked glycosylation sites are very expensive. Therefore, the prediction of N-linked glycosylation sites has become an important research field.</p><p><strong>Results: </strong>In this work, we propose StackGlyEmbed, a stacking ensemble machine learning model, to computationally predict N-linked glycosylation sites. We have explored embeddings from several protein language models and built the stacking ensemble using Support Vector Machine (SVM), Extreme Gradient Boosting (XGB) and <i>K</i>-nearest Neighbor (KNN) learners in the base layer, with a second SVM model in the meta layer. StackGlyEmbed achieves 98.2% sensitivity, 92.5% balanced accuracy, 89.1% F1-score and 82.6% Matthew's correlation coefficient in independent testing, outperforming the existing state-of-the-art methods.</p><p><strong>Availability and implementation: </strong>StackGlyEmbed is freely available at: https://github.com/nafcoder/StackGlyEmbed.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"5 1","pages":"vbaf146"},"PeriodicalIF":2.8000,"publicationDate":"2025-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12237515/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbaf146","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: N-linked glycosylation is one of the most basic post-translational modifications (PTMs) where oligosaccharides covalently bond with Asparagine (N). These are found in the conserved regions like N-X-S or N-X-T where X can be any residue except Proline (P). Prediction of N-linked glycosylation sites has great importance as these PTMs play a vital role in many biological processes and functionalities. Experimental methods, such as mass spectrometry, for detecting N-linked glycosylation sites are very expensive. Therefore, the prediction of N-linked glycosylation sites has become an important research field.
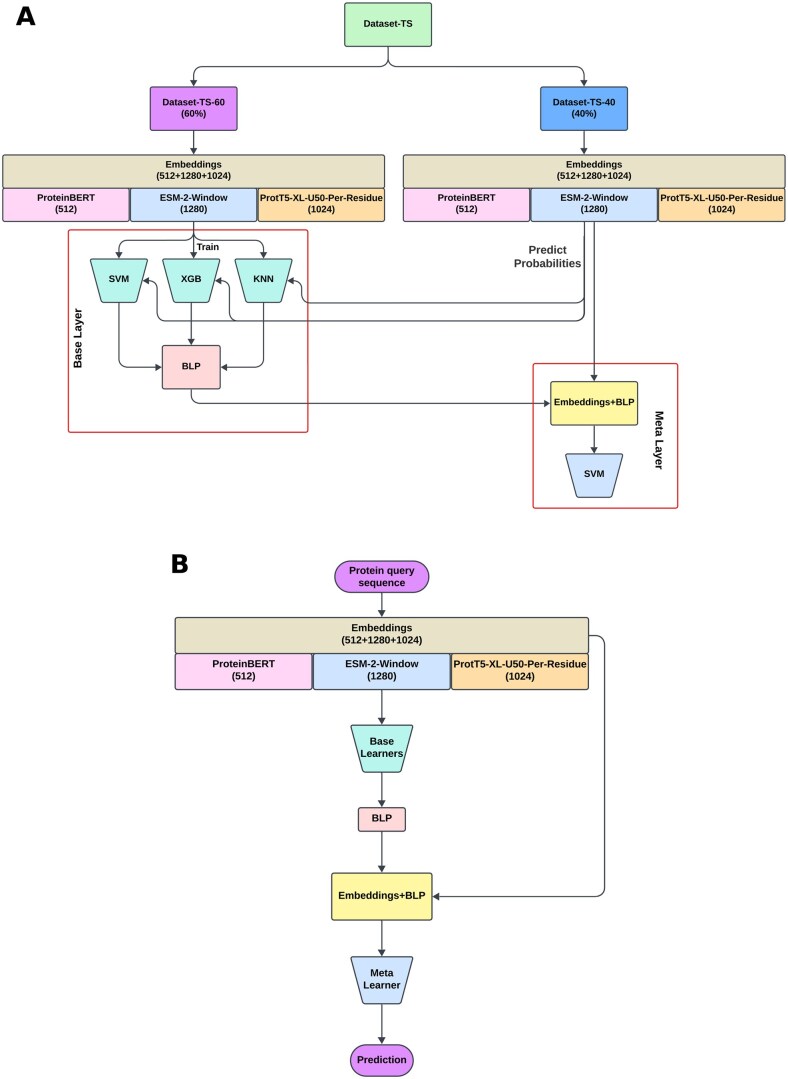
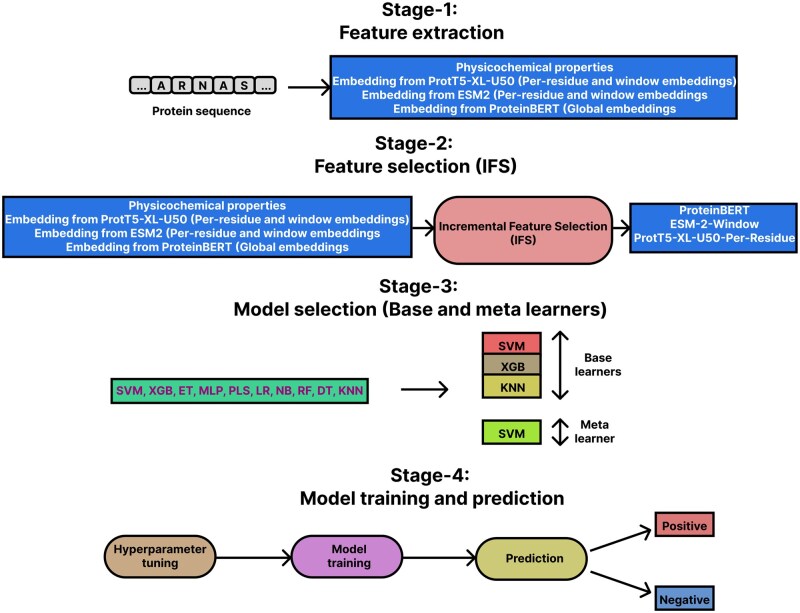
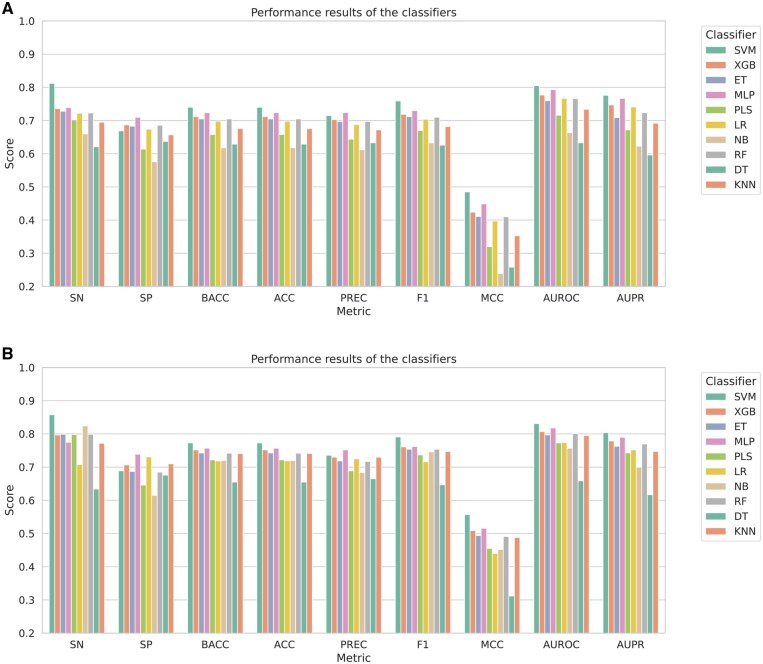
Results: In this work, we propose StackGlyEmbed, a stacking ensemble machine learning model, to computationally predict N-linked glycosylation sites. We have explored embeddings from several protein language models and built the stacking ensemble using Support Vector Machine (SVM), Extreme Gradient Boosting (XGB) and K-nearest Neighbor (KNN) learners in the base layer, with a second SVM model in the meta layer. StackGlyEmbed achieves 98.2% sensitivity, 92.5% balanced accuracy, 89.1% F1-score and 82.6% Matthew's correlation coefficient in independent testing, outperforming the existing state-of-the-art methods.
Availability and implementation: StackGlyEmbed is freely available at: https://github.com/nafcoder/StackGlyEmbed.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


