Samantha Kanny, Grisha Post, Patricia Carbajales-Dale, William Cummings, Janet Evatt, Windsor Westbrook Sherrill
{"title":"A comparative approach of machine learning models to predict attrition in a diabetes management program.","authors":"Samantha Kanny, Grisha Post, Patricia Carbajales-Dale, William Cummings, Janet Evatt, Windsor Westbrook Sherrill","doi":"10.1371/journal.pdig.0000930","DOIUrl":null,"url":null,"abstract":"<p><p>Approximately 11.6% of Americans have diabetes and South Carolina has one of the highest rates of adults with diabetes. Diabetes self-management programs have been observed to be effective in promoting weight loss and improving diabetes knowledge and self-care behaviors. The ability to keep vulnerable individuals in these programs is critical to helping the growing diabetic population. Utilizing machine learning is gaining popularity in healthcare settings. The objective of this study is to assess the effectiveness of several machine learning methods in predicting attrition from a diabetes self-management program, utilizing participant demographics and various evaluation measures. Data were collected from participants enrolled in Health Extension for Diabetes (HED). Descriptive statistics were used to examine HED participant demographics, while Mann-Whitney U tests and chi-square tests were used to examine relationships between demographics and pre-program evaluation measures. Through the various analyses, health-related measures - specifically the SF-12 quality of life scores, Distressed Communities Index (DCI) score, along with demographic factors (race, age, height, and educational attainment), and spatial variables (drive time to the nearest grocery store) emerged as influential predictors of attrition. However, the machine learning models showed poor overall performance, with AUC values ranging from 0.53 - 0.64 and F-1 scores between 0.19 - 0.36, indicating low predictive power. Among the models tested, XGBoost with downsampling yielded the highest AUC value (0.64) and a slightly higher F-1 score (0.36). To enhance model interpretability, SHAP (SHapley Additive exPlanations) was applied. While these models are not suitable for accurately predicting individual attrition risk in diabetes self-management programs, they identify potential factors influencing dropout rates. These findings underscore the difficulty for models to accurately predict health behavior outcomes, highlighting the need for future research to improve predictive modeling to better support patient engagement and retention.</p>","PeriodicalId":74465,"journal":{"name":"PLOS digital health","volume":"4 7","pages":"e0000930"},"PeriodicalIF":7.7000,"publicationDate":"2025-07-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12233248/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"PLOS digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1371/journal.pdig.0000930","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/7/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
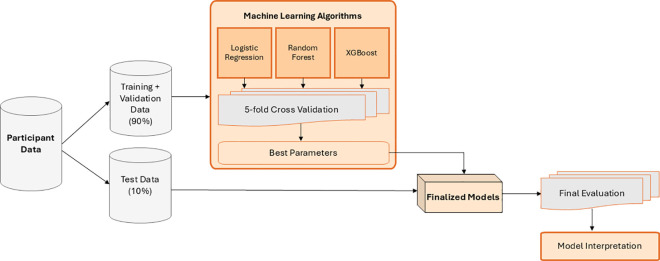
Approximately 11.6% of Americans have diabetes and South Carolina has one of the highest rates of adults with diabetes. Diabetes self-management programs have been observed to be effective in promoting weight loss and improving diabetes knowledge and self-care behaviors. The ability to keep vulnerable individuals in these programs is critical to helping the growing diabetic population. Utilizing machine learning is gaining popularity in healthcare settings. The objective of this study is to assess the effectiveness of several machine learning methods in predicting attrition from a diabetes self-management program, utilizing participant demographics and various evaluation measures. Data were collected from participants enrolled in Health Extension for Diabetes (HED). Descriptive statistics were used to examine HED participant demographics, while Mann-Whitney U tests and chi-square tests were used to examine relationships between demographics and pre-program evaluation measures. Through the various analyses, health-related measures - specifically the SF-12 quality of life scores, Distressed Communities Index (DCI) score, along with demographic factors (race, age, height, and educational attainment), and spatial variables (drive time to the nearest grocery store) emerged as influential predictors of attrition. However, the machine learning models showed poor overall performance, with AUC values ranging from 0.53 - 0.64 and F-1 scores between 0.19 - 0.36, indicating low predictive power. Among the models tested, XGBoost with downsampling yielded the highest AUC value (0.64) and a slightly higher F-1 score (0.36). To enhance model interpretability, SHAP (SHapley Additive exPlanations) was applied. While these models are not suitable for accurately predicting individual attrition risk in diabetes self-management programs, they identify potential factors influencing dropout rates. These findings underscore the difficulty for models to accurately predict health behavior outcomes, highlighting the need for future research to improve predictive modeling to better support patient engagement and retention.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


