Yavuz Yigit, Asım Enes Ozbek, Betul Dogru, Serkan Gunay, Baha AlKahlout
{"title":"Evaluating large language models for renal colic imaging recommendations: a comparative analysis of Gemini, copilot, and ChatGPT-4.0.","authors":"Yavuz Yigit, Asım Enes Ozbek, Betul Dogru, Serkan Gunay, Baha AlKahlout","doi":"10.1186/s12245-025-00895-3","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The field of natural language processing (NLP) has evolved significantly since its inception in the 1950s, with large language models (LLMs) now playing a crucial role in addressing medical challenges.</p><p><strong>Objectives: </strong>This study evaluates the alignment of three prominent LLMs-Gemini, Copilot, and ChatGPT-4.0-with expert consensus on imaging recommendations for acute flank pain.</p><p><strong>Methods: </strong>A total of 29 clinical vignettes representing different combinations of age, sex, pregnancy status, likelihood of stone disease, and alternative diagnoses were posed to the three LLMs (Gemini, Copilot, and ChatGPT-4.0) between March and April 2024. Responses were compared to the consensus recommendations of a multispecialty panel. The primary outcome was the rate of LLM responses matching the majority consensus. Secondary outcomes included alignment with consensus-rated perfect (9/9) or excellent (8/9) responses and agreement with any of the nine panel members.</p><p><strong>Results: </strong>Gemini aligned with the majority consensus in 65.5% of cases, compared to 41.4% for both Copilot and ChatGPT-4.0. In scenarios rated as perfect or excellent by the consensus, Gemini showed 69.5% agreement, significantly higher than Copilot and ChatGPT-4.0, both at 43.4% (p = 0.045 and < 0.001, respectively). Overall, Gemini demonstrated an agreement rate of 82.7% with any of the nine reviewers, indicating superior capability in addressing complex medical inquiries.</p><p><strong>Conclusion: </strong>Gemini consistently outperformed Copilot and ChatGPT-4.0 in aligning with expert consensus, suggesting its potential as a reliable tool in clinical decision-making. Further research is needed to enhance the reliability and accuracy of LLMs and to address the ethical and legal challenges associated with their integration into healthcare systems.</p>","PeriodicalId":13967,"journal":{"name":"International Journal of Emergency Medicine","volume":"18 1","pages":"123"},"PeriodicalIF":2.0000,"publicationDate":"2025-07-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12232162/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Emergency Medicine","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s12245-025-00895-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"EMERGENCY MEDICINE","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The field of natural language processing (NLP) has evolved significantly since its inception in the 1950s, with large language models (LLMs) now playing a crucial role in addressing medical challenges.
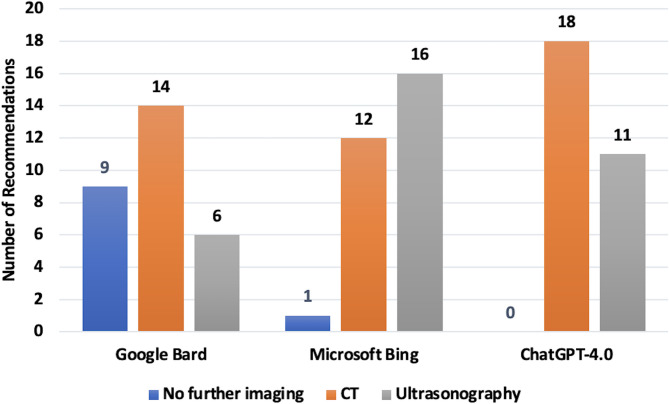
Objectives: This study evaluates the alignment of three prominent LLMs-Gemini, Copilot, and ChatGPT-4.0-with expert consensus on imaging recommendations for acute flank pain.
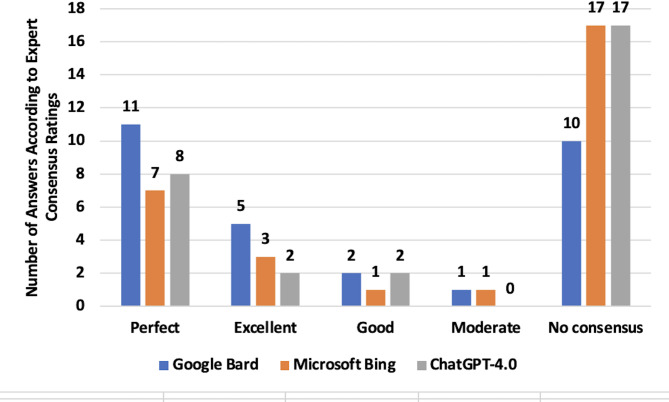
Methods: A total of 29 clinical vignettes representing different combinations of age, sex, pregnancy status, likelihood of stone disease, and alternative diagnoses were posed to the three LLMs (Gemini, Copilot, and ChatGPT-4.0) between March and April 2024. Responses were compared to the consensus recommendations of a multispecialty panel. The primary outcome was the rate of LLM responses matching the majority consensus. Secondary outcomes included alignment with consensus-rated perfect (9/9) or excellent (8/9) responses and agreement with any of the nine panel members.
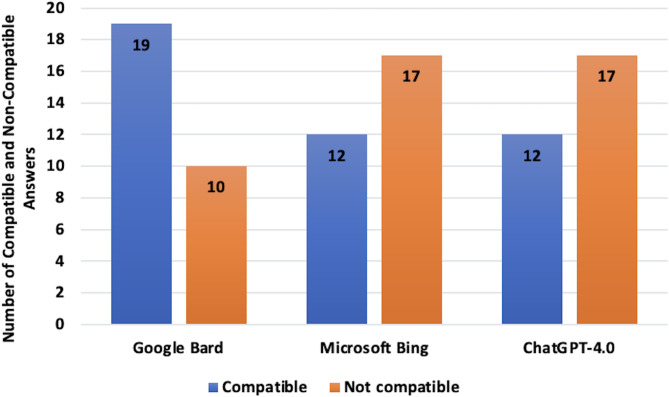
Results: Gemini aligned with the majority consensus in 65.5% of cases, compared to 41.4% for both Copilot and ChatGPT-4.0. In scenarios rated as perfect or excellent by the consensus, Gemini showed 69.5% agreement, significantly higher than Copilot and ChatGPT-4.0, both at 43.4% (p = 0.045 and < 0.001, respectively). Overall, Gemini demonstrated an agreement rate of 82.7% with any of the nine reviewers, indicating superior capability in addressing complex medical inquiries.
Conclusion: Gemini consistently outperformed Copilot and ChatGPT-4.0 in aligning with expert consensus, suggesting its potential as a reliable tool in clinical decision-making. Further research is needed to enhance the reliability and accuracy of LLMs and to address the ethical and legal challenges associated with their integration into healthcare systems.
期刊介绍:
The aim of the journal is to bring to light the various clinical advancements and research developments attained over the world and thus help the specialty forge ahead. It is directed towards physicians and medical personnel undergoing training or working within the field of Emergency Medicine. Medical students who are interested in pursuing a career in Emergency Medicine will also benefit from the journal. This is particularly useful for trainees in countries where the specialty is still in its infancy. Disciplines covered will include interesting clinical cases, the latest evidence-based practice and research developments in Emergency medicine including emergency pediatrics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


