Identifying Asthma-Related Symptoms From Electronic Health Records Using a Hybrid Natural Language Processing Approach Within a Large Integrated Health Care System: Retrospective Study.
Fagen Xie, Robert S Zeiger, Mary Marycania Saparudin, Sahar Al-Salman, Eric Puttock, William Crawford, Michael Schatz, Stanley Xu, William M Vollmer, Wansu Chen
{"title":"Identifying Asthma-Related Symptoms From Electronic Health Records Using a Hybrid Natural Language Processing Approach Within a Large Integrated Health Care System: Retrospective Study.","authors":"Fagen Xie, Robert S Zeiger, Mary Marycania Saparudin, Sahar Al-Salman, Eric Puttock, William Crawford, Michael Schatz, Stanley Xu, William M Vollmer, Wansu Chen","doi":"10.2196/69132","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Asthma-related symptoms are significant predictors of asthma exacerbation. Most of these symptoms are documented in clinical notes in a free-text format, and effective methods for capturing asthma-related symptoms from unstructured data are lacking.</p><p><strong>Objective: </strong>The study aims to develop a natural language processing (NLP) algorithm for identifying symptoms associated with asthma from clinical notes within a large integrated health care system.</p><p><strong>Methods: </strong>We analyzed unstructured clinical notes within 2 years before a visit with asthma diagnosis in 2013-2018 and 2021-2022 to identify 4 common asthma-related symptoms. Related terms and phrases were initially compiled from publicly available resources and then refined through clinician input and chart review. A rule-based NLP algorithm was iteratively developed and refined via multiple rounds of chart review followed by adjudication. Subsequently, transformer-based deep learning algorithms were trained using the same manually annotated datasets. A hybrid NLP algorithm was then generated by combining rule-based and transformer-based algorithms. The hybrid NLP algorithm was finally applied to the implementation notes.</p><p><strong>Results: </strong>A total of 11,374,552 eligible clinical notes with 128,211,793 sentences were analyzed. After applying the hybrid algorithm to implementation notes, at least 1 asthma-related symptom was identified in 1,663,450 out of 127,763,086 (1.3%) sentences and 858,350 out of 11,364,952 (7.55%) notes, respectively. Cough was the most frequently identified at both the sentence (1,363,713/127,763,086, 1.07%) and note (660,685/11,364,952, 5.81%) levels, while chest tightness was the least frequent at both the sentence (141,733/127,763,086, 0.11%) and note (64,251/11,364,952, 0.57%) levels. The frequency of multiple symptoms ranged from 0.03% (36,057/127,763,086) to 0.38% (484,050/127,763,086) at the sentence level and 0.10% (10,954/11,364,952) to 1.85% (209,805/11,364,952) at the note level. Validation against 1600 manually annotated clinical notes yielded a positive predictive value ranging from 96.53% (wheezing) to 97.42% (chest tightness) at the sentence level and 96.76% (wheezing) to 97.42% (chest tightness) at the note level. Sensitivity ranged from 93.9% (dyspnea) to 95.95% (cough) at the sentence level and 96% (chest tightness) to 99.07% (cough) at the note level. All 4 symptoms had F1-scores greater than 0.95 at both the sentence and note levels, regardless of NLP algorithms.</p><p><strong>Conclusions: </strong>The developed NLP algorithms could effectively capture asthma-related symptoms from unstructured clinical notes. These algorithms could be used to facilitate early asthma detection and predict exacerbation risk.</p>","PeriodicalId":73551,"journal":{"name":"JMIR AI","volume":"4 ","pages":"e69132"},"PeriodicalIF":2.0000,"publicationDate":"2025-05-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12231518/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR AI","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/69132","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Asthma-related symptoms are significant predictors of asthma exacerbation. Most of these symptoms are documented in clinical notes in a free-text format, and effective methods for capturing asthma-related symptoms from unstructured data are lacking.
Objective: The study aims to develop a natural language processing (NLP) algorithm for identifying symptoms associated with asthma from clinical notes within a large integrated health care system.
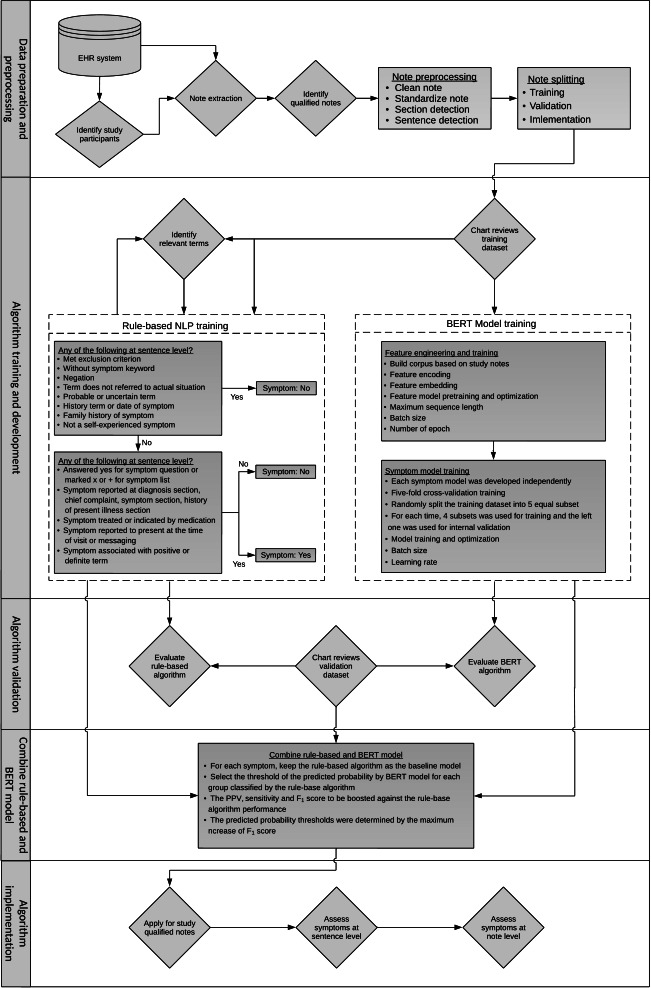
Methods: We analyzed unstructured clinical notes within 2 years before a visit with asthma diagnosis in 2013-2018 and 2021-2022 to identify 4 common asthma-related symptoms. Related terms and phrases were initially compiled from publicly available resources and then refined through clinician input and chart review. A rule-based NLP algorithm was iteratively developed and refined via multiple rounds of chart review followed by adjudication. Subsequently, transformer-based deep learning algorithms were trained using the same manually annotated datasets. A hybrid NLP algorithm was then generated by combining rule-based and transformer-based algorithms. The hybrid NLP algorithm was finally applied to the implementation notes.
Results: A total of 11,374,552 eligible clinical notes with 128,211,793 sentences were analyzed. After applying the hybrid algorithm to implementation notes, at least 1 asthma-related symptom was identified in 1,663,450 out of 127,763,086 (1.3%) sentences and 858,350 out of 11,364,952 (7.55%) notes, respectively. Cough was the most frequently identified at both the sentence (1,363,713/127,763,086, 1.07%) and note (660,685/11,364,952, 5.81%) levels, while chest tightness was the least frequent at both the sentence (141,733/127,763,086, 0.11%) and note (64,251/11,364,952, 0.57%) levels. The frequency of multiple symptoms ranged from 0.03% (36,057/127,763,086) to 0.38% (484,050/127,763,086) at the sentence level and 0.10% (10,954/11,364,952) to 1.85% (209,805/11,364,952) at the note level. Validation against 1600 manually annotated clinical notes yielded a positive predictive value ranging from 96.53% (wheezing) to 97.42% (chest tightness) at the sentence level and 96.76% (wheezing) to 97.42% (chest tightness) at the note level. Sensitivity ranged from 93.9% (dyspnea) to 95.95% (cough) at the sentence level and 96% (chest tightness) to 99.07% (cough) at the note level. All 4 symptoms had F1-scores greater than 0.95 at both the sentence and note levels, regardless of NLP algorithms.
Conclusions: The developed NLP algorithms could effectively capture asthma-related symptoms from unstructured clinical notes. These algorithms could be used to facilitate early asthma detection and predict exacerbation risk.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


